Bài viết & Thông báo
Cập nhật bài viết và thông báo mới nhất từ khoa An toàn Thông tin
28 kết quả#Cybersecurity
 blogs
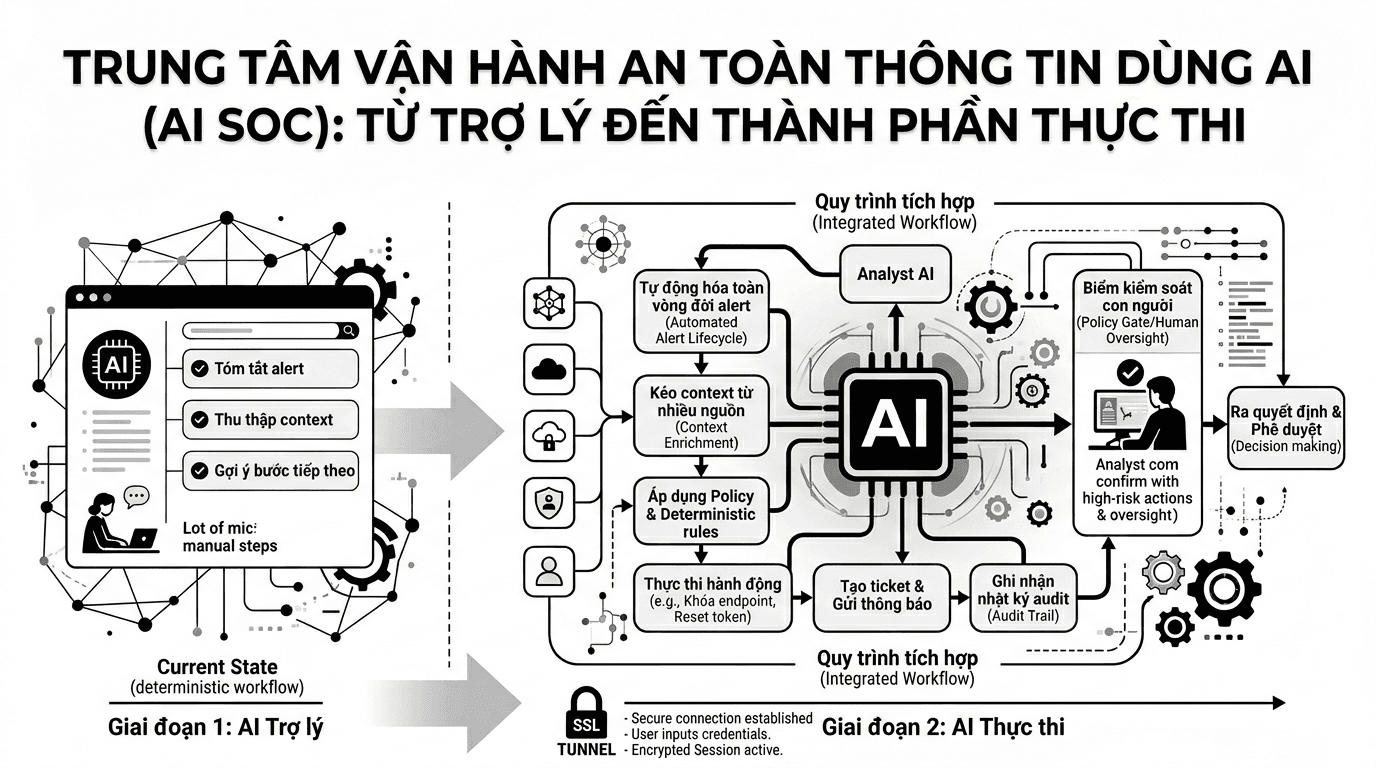
blogsAI SOC không nằm ở chỗ hiểu alert nhanh hơn, mà ở chỗ xử lý được công việc đến cùng
Nhiều hệ thống AI SOC hiện nay mới chỉ giúp analyst đọc alert nhanh hơn, gom context nhanh hơn và viết tóm tắt đẹp hơn. Giá trị thực chỉ xuất hiện khi AI đi vào workflow, thực hiện được các bước xử lý có kiểm soát, phối hợp được nhiều công cụ, ghi lại đầy đủ dấu vết và chỉ đẩy con người vào các điểm cần phán đoán hoặc phê duyệt.
 blogs
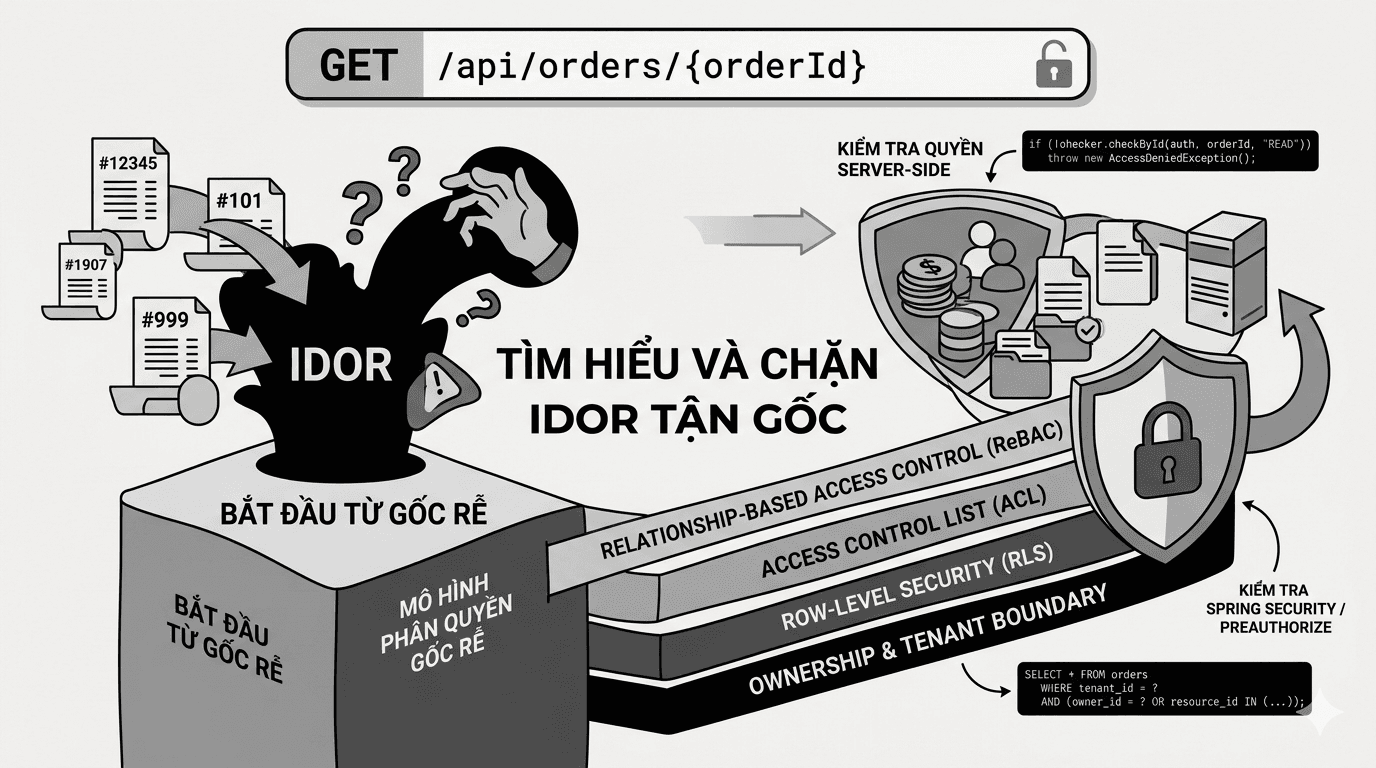
blogsLỗ hổng IDOR không chỉ là lỗi kiểm tra id, mà là thất bại của tư duy phân quyền theo tài nguyên
IDOR không chỉ là lỗi đổi một ID trong URL mà là biểu hiện trực tiếp của Broken Access Control khi hệ thống truy xuất tài nguyên dựa trên object reference do client cung cấp nhưng không ràng buộc quyền thực tế của caller trên resource đó. Muốn xử lý tận gốc, ứng dụng phải chuyển từ tư duy kiểm tra chức năng đơn thuần sang authorization theo tài nguyên, kết hợp ownership, tenant boundary, ACL, kế thừa quyền, kiểm soát ở tầng service, repository và database để chặn truy cập trái phép một cách nhất quán.
 blogs
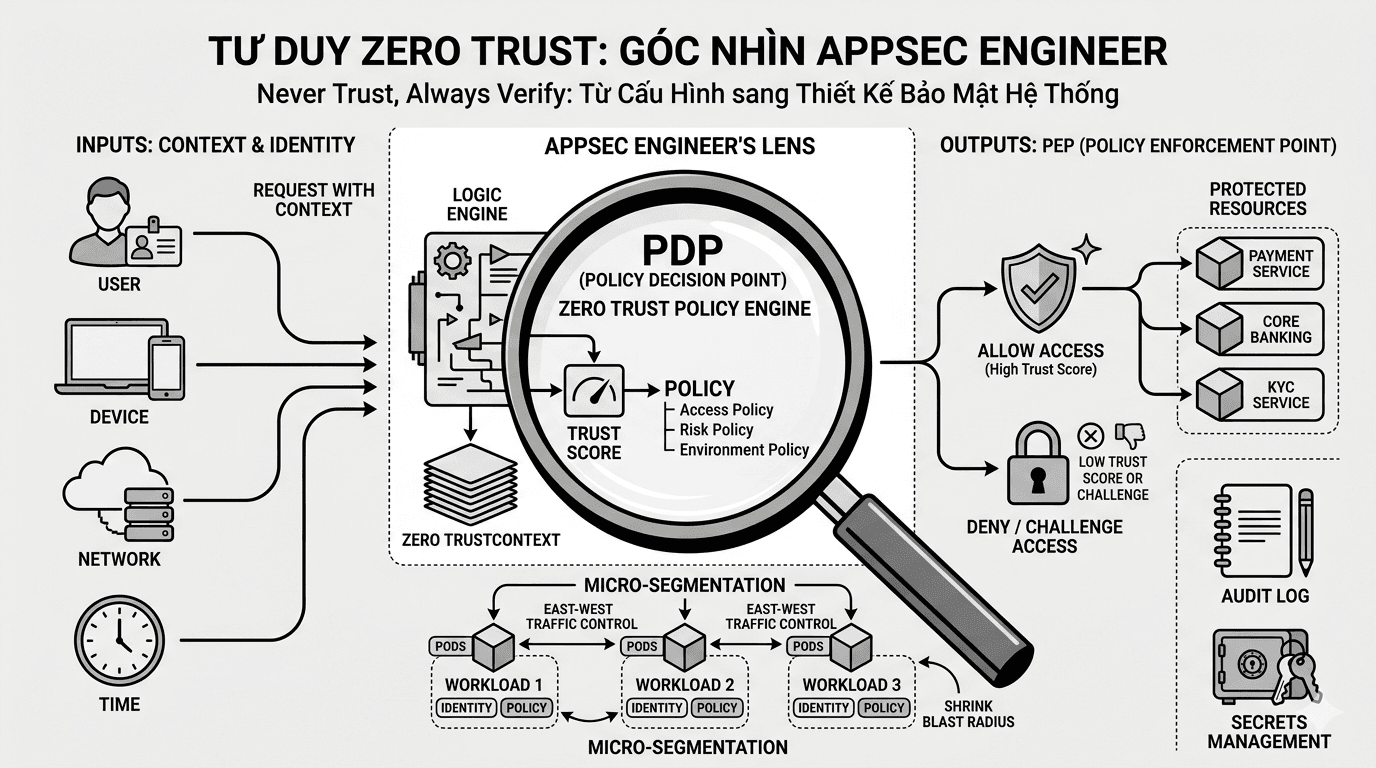
blogsZero trust architecture dưới góc nhìn của một appsec engineer
Nếu nhìn từ góc độ của một AppSec engineer, Zero Trust Architecture không chỉ là câu chuyện của hạ tầng mạng hay sản phẩm bảo mật. Đây là một cách thiết kế hệ thống sao cho mọi truy cập đều phải đi qua các giả định tin cậy rõ ràng, các điểm kiểm soát có chủ đích, và các quyết định truy cập có thể kiểm chứng. Giá trị lớn nhất của Zero Trust nằm ở chỗ nó buộc kiến trúc phải trả lời được ai đang truy cập, từ đâu, bằng thiết bị nào, tới tài nguyên gì, với mức rủi ro nào, và trong ngữ cảnh nào thì được phép đi tiếp. Với AppSec designer, đây chính là cách chuyển bảo mật từ tầng khẩu hiệu sang tầng kiến trúc và cơ chế thực thi.
 blogs
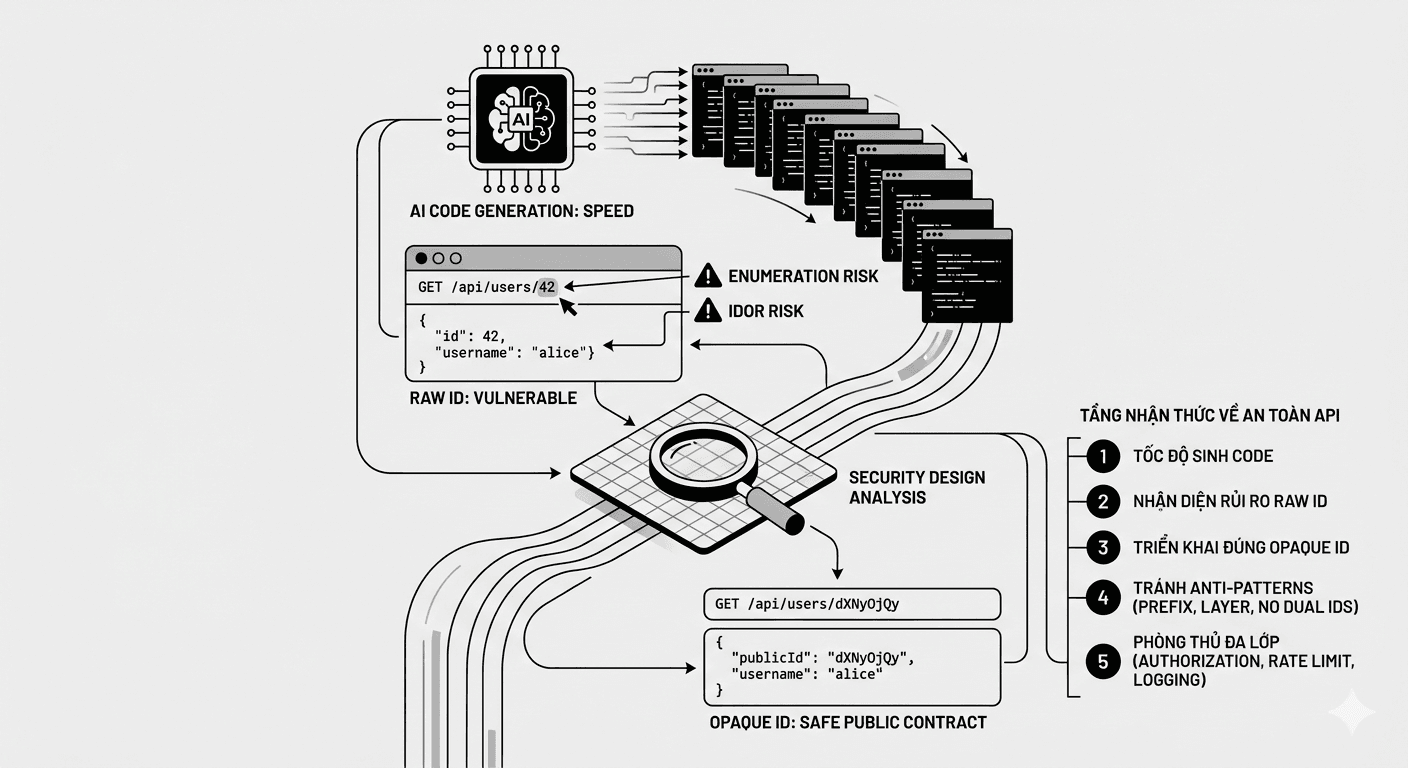
blogsCùng xem, khi AI tham gia viết code, năng lực thiết kế mới quyết định hệ thống an toàn đến đâu (Opaque ID Design)
AI đang giúp lập trình viên tạo API nhanh hơn, nhưng cũng đang làm lộ rõ khoảng cách giữa viết được mã và hiểu được hệ thống mình đang xây. Một ví dụ điển hình là việc nhiều ứng dụng vẫn công khai primary key của cơ sở dữ liệu ra ngoài endpoint, từ đó mở đường cho lỗi tham chiếu đối tượng trực tiếp không an toàn (Insecure Direct Object Reference, IDOR). Định danh mờ (Opaque ID) là một quyết định thiết kế hữu ích để giảm khả năng suy diễn và enumeration, nhưng giá trị thật của nó chỉ xuất hiện khi người làm hiểu đúng bản chất, tránh các anti pattern, và đặt nó trong bức tranh tổng thể của authorization, validation, logging, transaction, cache, và kiểm soát rủi ro toàn hệ thống. Trong thời đại AI, lợi thế không còn nằm ở tốc độ sinh mã, mà nằm ở chiều sâu nhận thức về hậu quả thiết kế.
 blogs
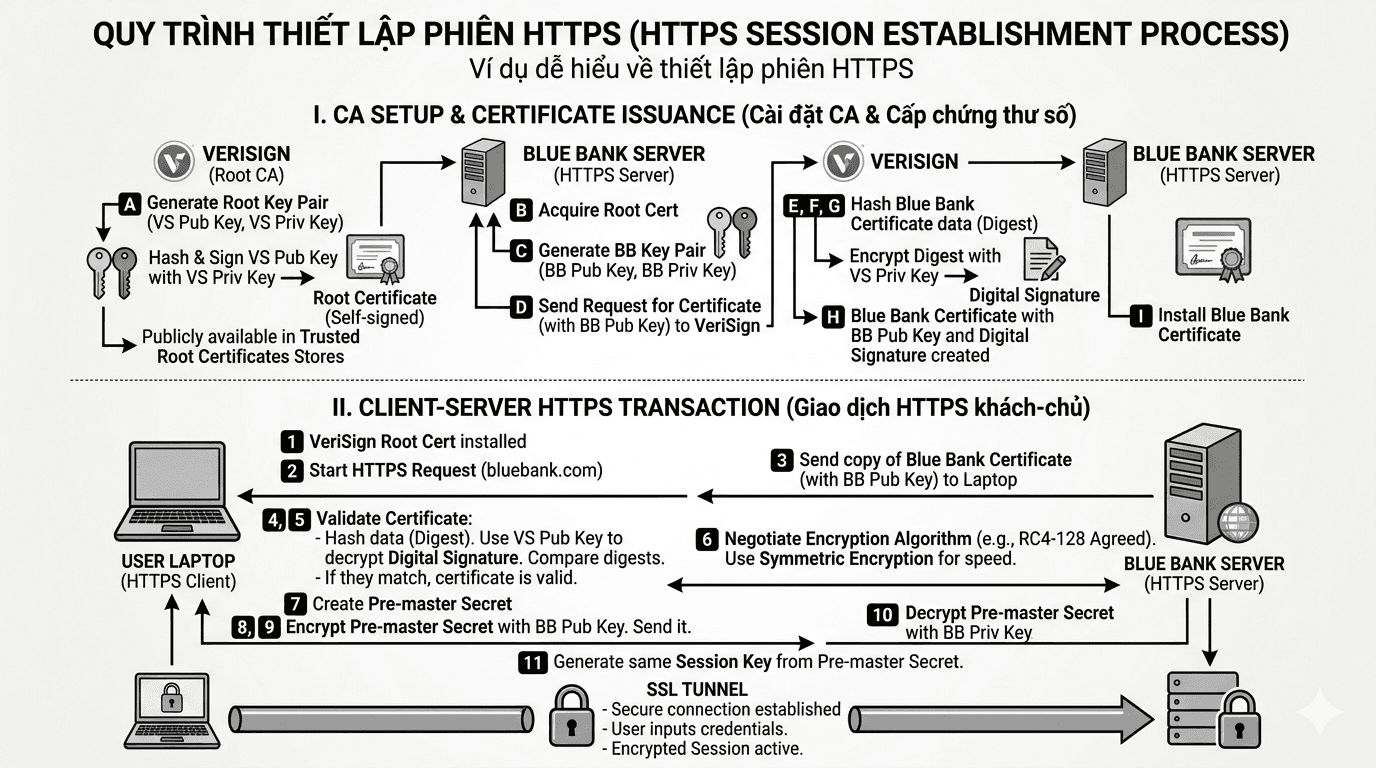
blogsHTTPS Session
Với vai trò là một CA gốc (root CA), máy chủ VeriSign đã tạo một cặp khóa (VS Pub Key – khóa công khai, VS Priv Key – khóa riêng). VeriSign sử dụng VS Priv Key để ký vào VS Pub Key của mình và tạo ra chứng thư số gốc (Root certificate, CA certificate) – đây được gọi là chứng thư số tự ký (self-signed certificate). (Việc ký chứng thư số sẽ được đề cập trong Bước E.) Lưu ý, các tổ chức lớn và quan trọng như VeriSign không dùng chứng thư gốc cao nhất của họ để ký chứng thư khách hàng mà sẽ sử dụng hệ thống phân cấp của các CA.
 blogs
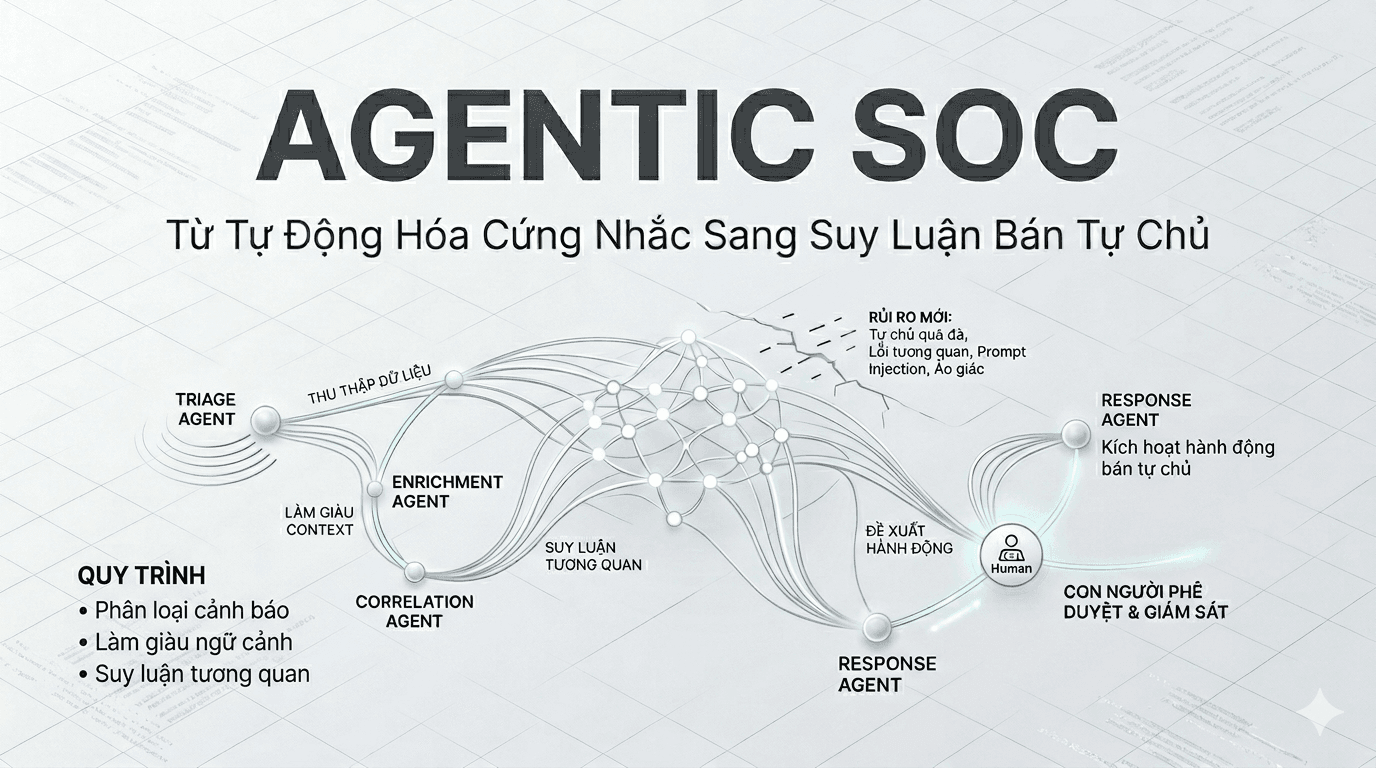
blogsAgentic SOC 2026: Khi AI Agent Tham Gia vào Trung Tâm Giám Sát Bảo Mật
"Agentic SOC không đơn thuần là thêm một module AI vào hệ thống. Đó là sự tiến hóa từ những kịch bản (playbook) cứng nhắc sang mô hình suy luận bán tự chủ. Khám phá cách các AI Agent giải quyết bài toán 'nhiễu' dữ liệu, làm giàu ngữ cảnh sự cố và lộ trình 4 giai đoạn để triển khai một SOC thông minh nhưng vẫn trong tầm kiểm soát.
 blogs
blogsKiến thức cơ bản về mật mã học cho kỹ sư phần mềm và kỹ sư an toàn ứng dụng
Mật mã học (cryptography) nên được xem như một công cụ giảm thiểu ở mức kiến trúc (architectural mitigation tool), có nhiệm vụ bảo vệ tính bí mật (confidentiality), tính toàn vẹn (integrity), tính xác thực (authenticity) và trách nhiệm giải trình (accountability) khi được đặt đúng vị trí trong hệ thống và được quản lý xuyên suốt toàn bộ vòng đời của nó.
 Cybersafe
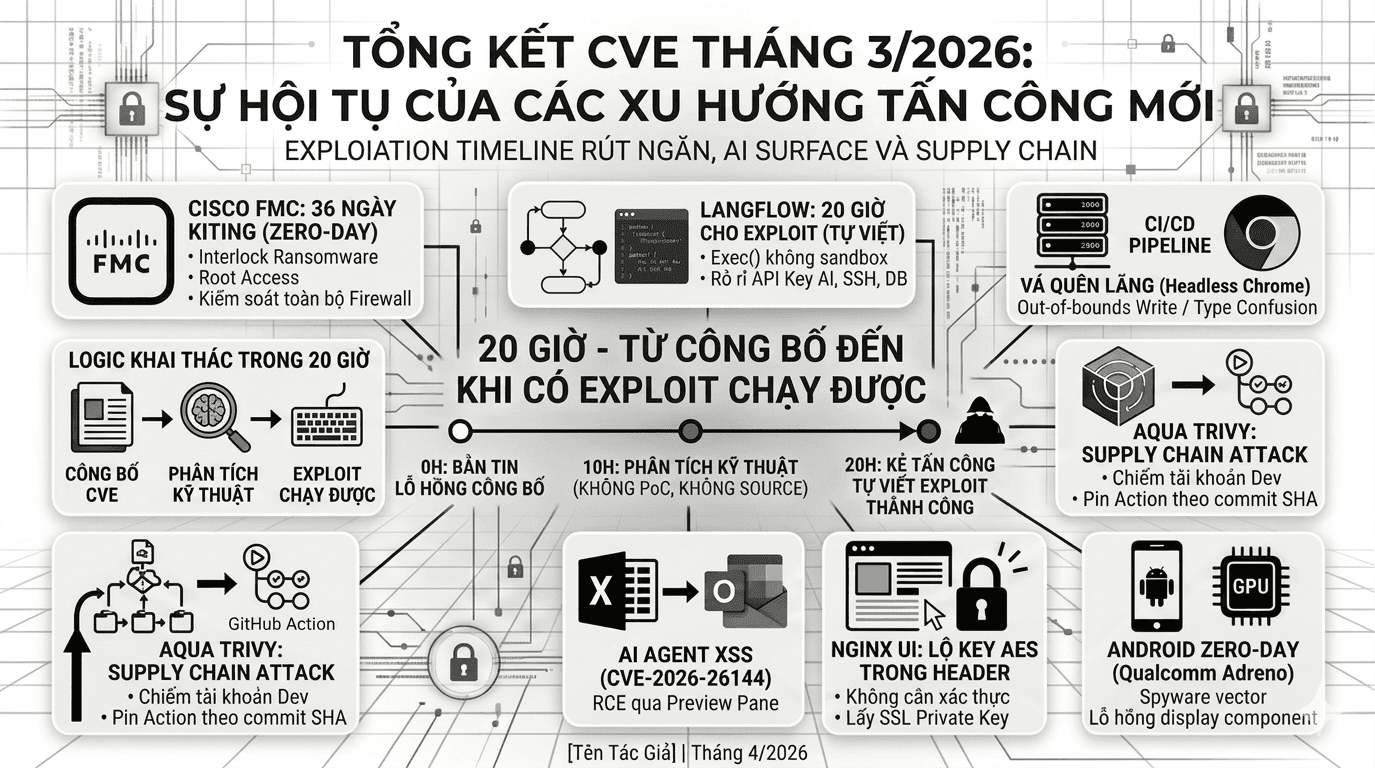
CybersafeCVE Tháng 3/2026: Thời Đại Exploit Được Viết Trong Vài Giờ
Tháng 3/2026 ghi nhận một kỷ lục không ai muốn chứng kiến: exploit hoạt động được viết ra chỉ 20 giờ sau khi CVE được công bố, không cần PoC, không cần mã nguồn rò rỉ. Từ lỗi Java deserialization CVSS 10.0 trong Cisco FMC bị ransomware group khai thác âm thầm suốt 36 ngày trước khi vendor biết, đến RCE không cần xác thực trên nền tảng AI Langflow với hơn 145.000 sao GitHub, rồi supply chain attack biến chính scanner bảo mật Aqua Trivy thành công cụ đánh cắp secret từ pipeline CI/CD của người dùng. Tháng này còn chứng kiến CVE đầu tiên khai thác trực tiếp AI co-pilot trong Microsoft Office như một vector exfiltration dữ liệu. Đây là tổng kết 9 lỗ hổng đáng chú ý nhất, cùng phân tích kỹ thuật và khuyến nghị xử lý thực tế cho từng trường hợp.
 blogs
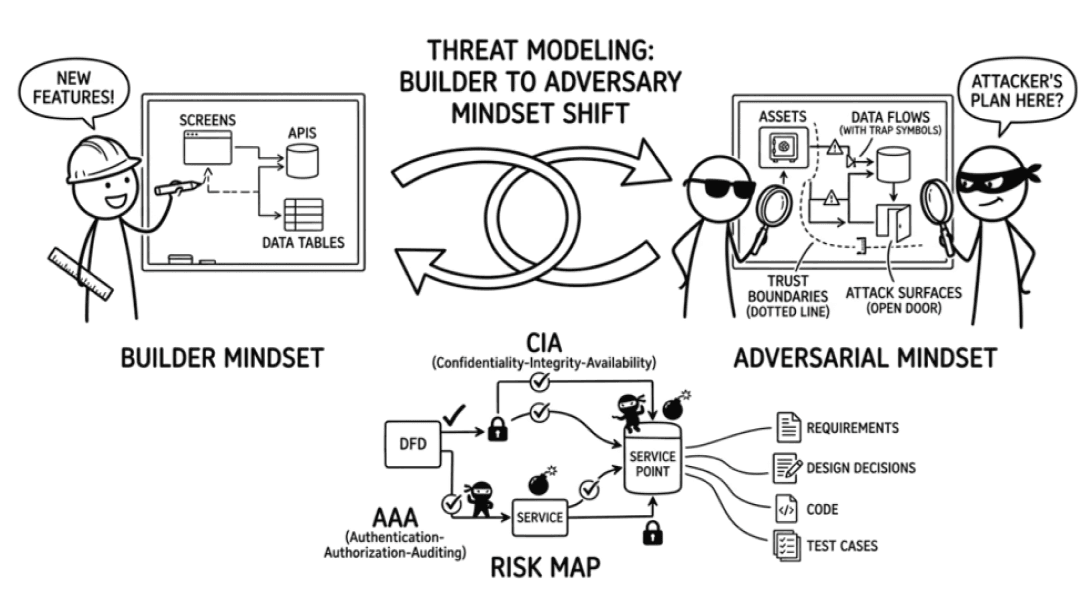
blogsThreat Modeling : đưa tư duy đối kháng vào thiết kế phần mềm từ sớm
Threat Modeling giúp đội phát triển đưa bảo mật vào đúng thời điểm, ngay khi hệ thống còn đang được mô hình hóa và thiết kế. Bằng cách nhìn hệ thống từ góc độ tài sản, ranh giới tin cậy, entry point, risk và misuse case, nhóm có thể phát hiện sớm các đường lạm dụng, ưu tiên đúng rủi ro và chuyển các quyết định bảo mật thành kiểm soát thực tế trước khi chi phí sửa đổi trở nên quá lớn.
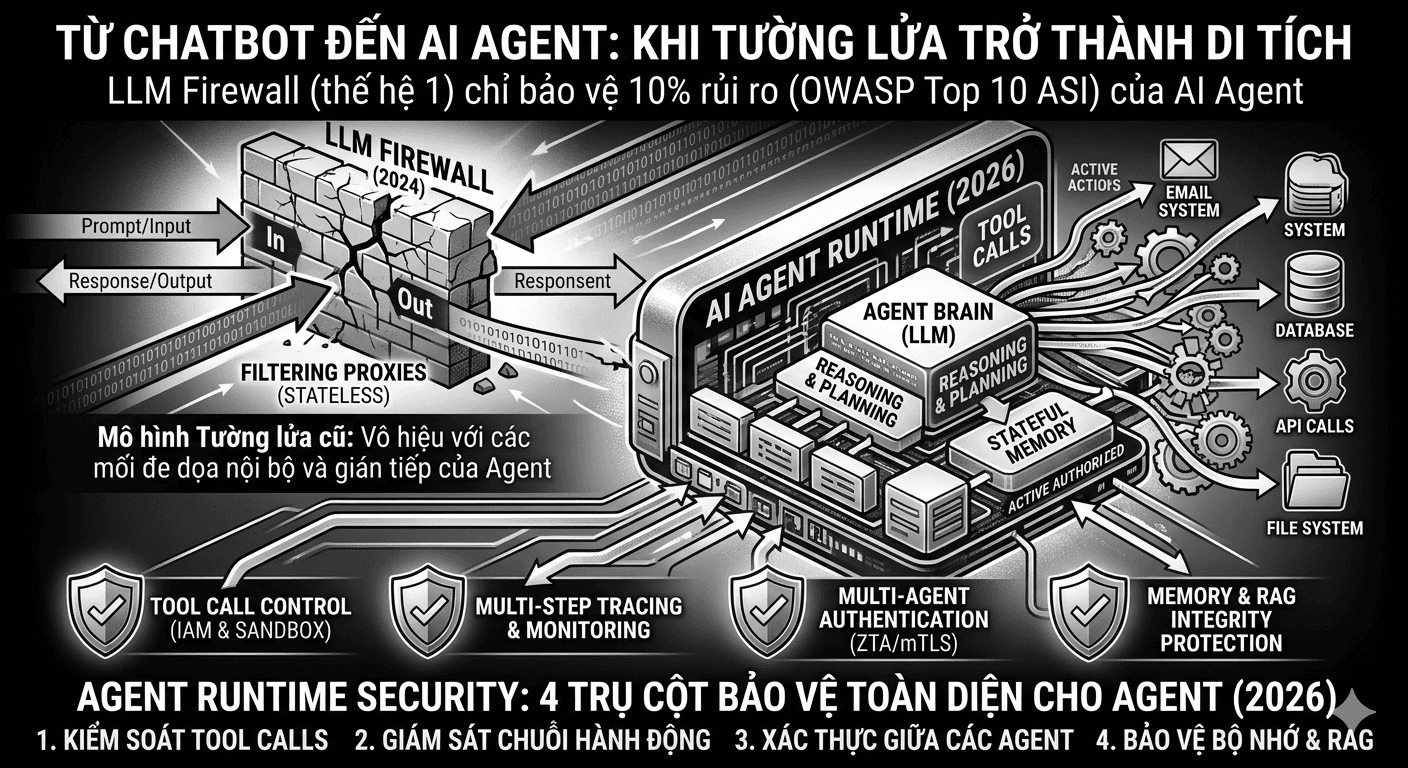 blogs
blogsLLM Firewall Lỗi Thời Trước Khi Kịp Ra Đời: Vì Sao Bảo Vệ Chatbot Không Còn Đủ Trong Thế Giới AI Agent
LLM Firewall không phải là sản phẩm tệ. Nó là sản phẩm đúng cho đúng thời điểm, nhưng thời điểm đó đã qua. Với bất kỳ tổ chức nào đang triển khai AI agent trong môi trường thực tế, câu hỏi không còn là "có nên bảo mật AI không" mà là "công cụ bảo mật mình đang dùng có được thiết kế cho đúng bài toán không".
 blogs
blogsChuyện Gì Xảy Ra Khi Hệ Thống Trí Tuệ Nhân Tạo Không Có Khóa Cửa?
Hạ tầng AI đang được triển khai nhanh hơn nhiều so với tốc độ mà cộng đồng bảo mật có thể theo kịp. Các đội ngũ kỹ thuật tập trung vào việc làm cho AI hoạt động, làm cho sản phẩm ra đời nhanh, và phần bảo vệ bị bỏ lại phía sau. Kẻ tấn công nhận ra điều này sớm hơn nhiều người nghĩ. Nếu tổ chức bạn đang dùng MCP trong môi trường thực tế, đây là thời điểm để kiểm tra lại cấu hình. Không phải vì ai đó đang nhắm vào bạn cụ thể, mà vì các scanner tự động không cần nhắm vào ai cụ thể. Chúng quét tất cả, và chúng không nghỉ.
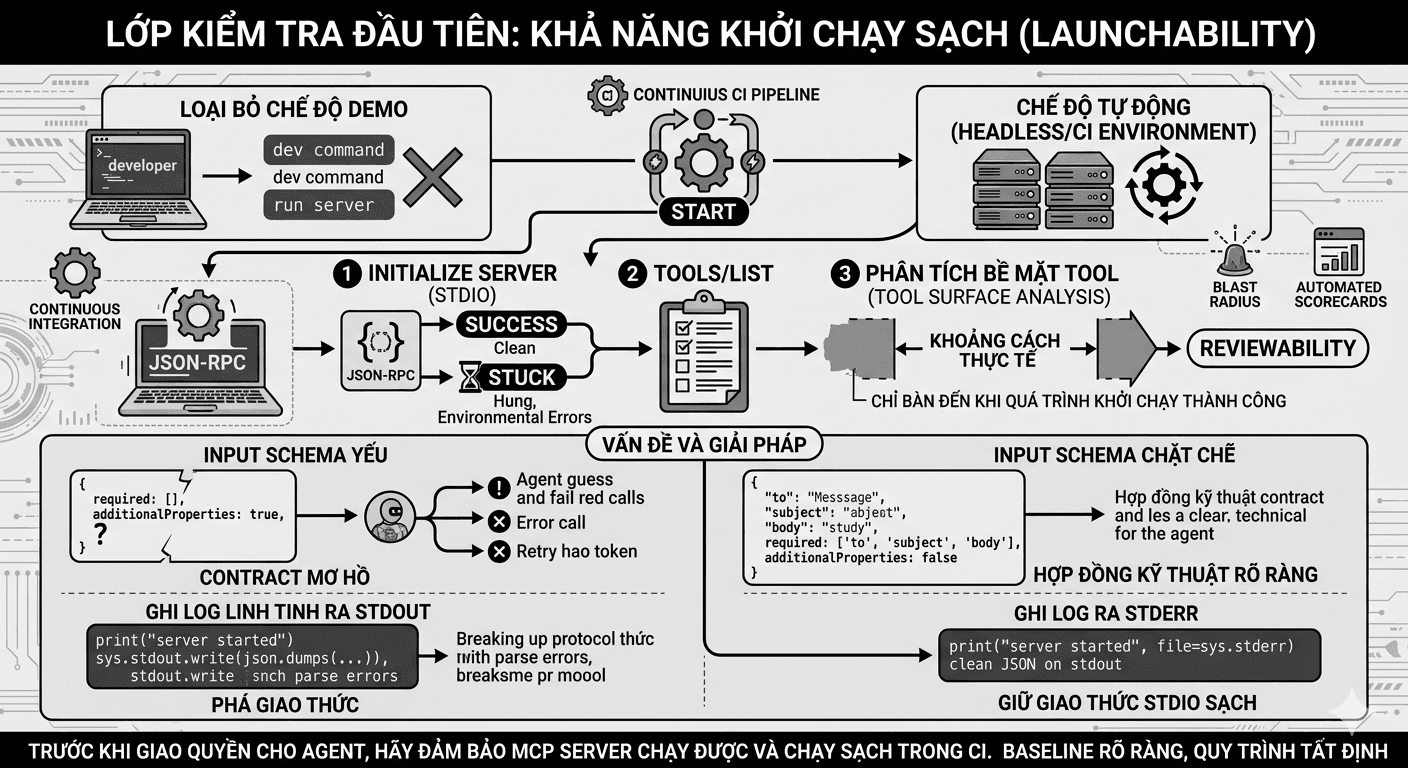 blogs
blogsTrước khi bàn đến security, tôi luôn hỏi MCP server có thật sự chạy được hay chưa
trước khi nói về security của mcp server, tôi luôn nhìn vào một lớp nền quan trọng hơn nhiều, đó là server có thật sự khởi chạy sạch, headless và đúng giao thức hay không. khi một server còn treo ở pha initialize, đổ log sai ra stdout, hoặc dùng input schema quá lỏng, thì mọi đánh giá cao hơn về trust, automation hay agent capability đều trở nên thiếu nền tảng. bài viết này đi thẳng vào vấn đề đó, xem mcp server như một boundary kỹ thuật cần được kiểm tra nghiêm túc bằng preflight, contract rõ ràng và quality gate có thể lặp lại trong ci.