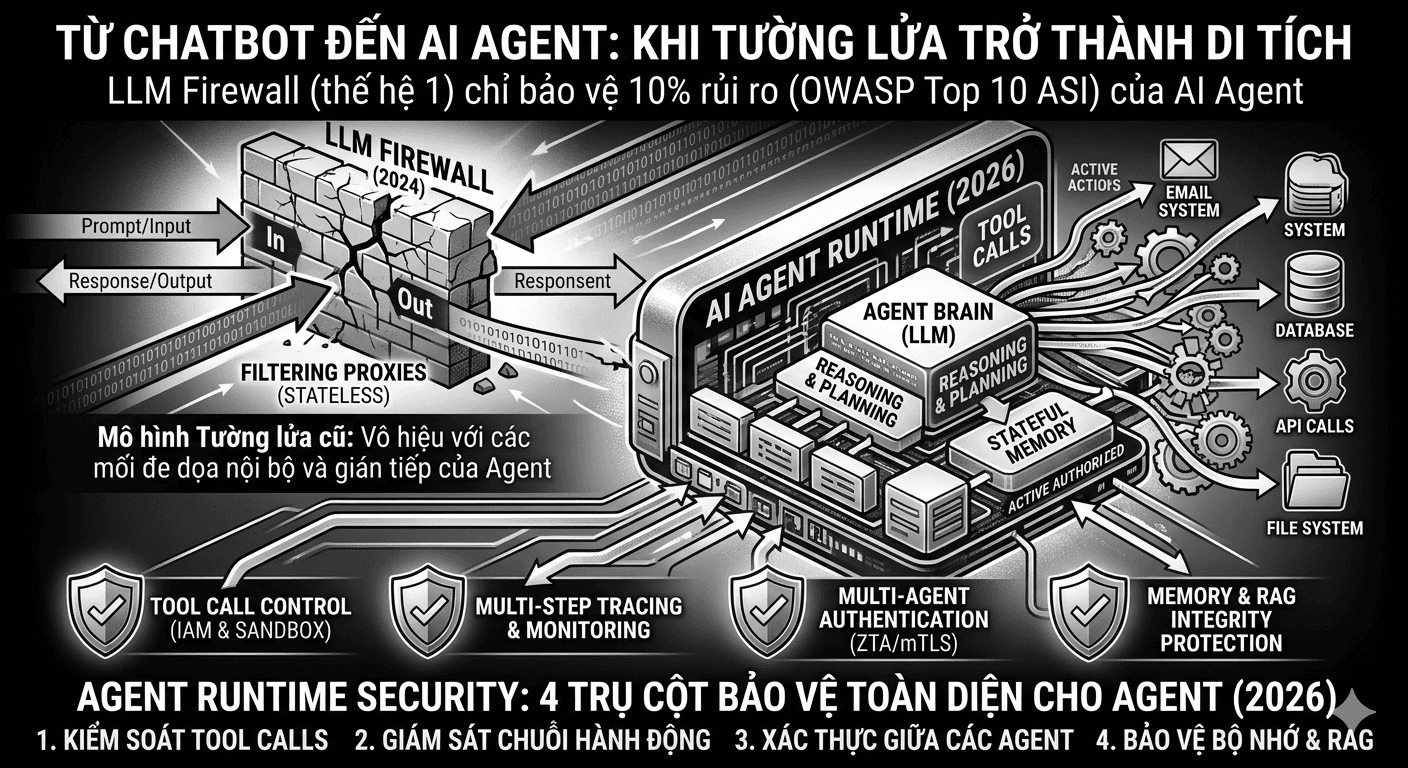
Có những sản phẩm ra đời đúng lúc. Và có những sản phẩm ra đời đúng lúc nhưng thế giới đã kịp thay đổi trước khi chúng hoàn thiện. LLM Firewall thuộc nhóm thứ hai. Đây là câu chuyện về một thế hệ công cụ bảo mật được thiết kế cho một bài toán, nhưng khi vừa đặt bút hoàn thiện thì bài toán đó đã bị thay thế bằng một bài toán khác khó hơn nhiều. Và hầu hết các tổ chức hiện nay vẫn đang dùng công cụ cũ để đối phó với mối đe dọa mới.
Vấn đề bắt đầu từ đâu?
Khi các doanh nghiệp bắt đầu tích hợp AI vào hệ thống của mình, mối lo ngại bảo mật tập trung vào một kịch bản đơn giản: làm thế nào để ngăn người dùng lợi dụng chatbot để làm những việc không được phép. Kịch bản đó trông như thế này: người dùng gõ một câu hỏi có hại vào ô chat, AI trả lời, và cần có thứ gì đó đứng giữa để lọc bỏ những gì nguy hiểm. Mối đe dọa chủ yếu xoay quanh ba thứ: prompt injection tức là chèn lệnh ẩn vào câu hỏi để qua mặt AI, jailbreak tức là tìm cách bẻ khóa các hạn chế của mô hình, và rò rỉ dữ liệu cá nhân trong câu trả lời.
Câu trả lời của thị trường lúc đó là hợp lý: đặt một lớp lọc giữa người dùng và mô hình AI. Giải pháp này được gọi là LLM Firewall.
LLM Firewall thế hệ đầu hoạt động như thế nào?
Về mặt kỹ thuật, LLM Firewall thế hệ đầu là một proxy không lưu trạng thái với hai lớp kiểm tra: lớp đầu vào lọc câu hỏi trước khi gửi đến AI, và lớp đầu ra kiểm tra câu trả lời trước khi trả về người dùng. Sơ đồ dưới đây minh họa kiến trúc của mô hình này:
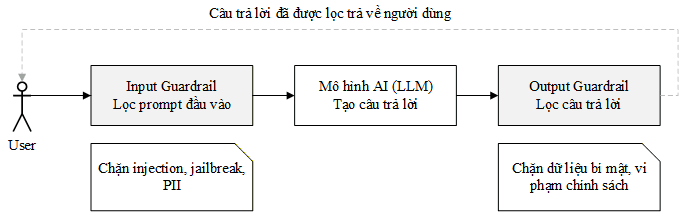
Mô hình này hoạt động tốt cho đúng một kịch bản: người dùng gõ câu hỏi, AI trả lời, xong. Một vòng, không có gì phức tạp hơn. Thị trường toàn cầu xây dựng xung quanh mô hình này khá nhanh với nhiều sản phẩm thương mại và mã nguồn mở. Quy mô thị trường được ước tính từ 30 triệu đến 260 triệu đô la, với kỳ vọng tăng trưởng mạnh trong năm 2026. Nhưng rồi mọi thứ thay đổi.
Thế giới chuyển sang AI agent và mọi thứ vỡ ra
Năm 2026, AI trong môi trường doanh nghiệp không còn là chatbot nữa. Nó là agent: một hệ thống trong đó mô hình AI không chỉ tạo ra văn bản mà còn đưa ra quyết định, gọi công cụ bên ngoài, truy cập cơ sở dữ liệu, gửi email, chạy lệnh trên hệ thống, và thậm chí phối hợp với các agent AI khác để hoàn thành nhiệm vụ phức tạp. Sự khác biệt giữa chatbot và agent không phải là khác biệt về mức độ, mà là khác biệt về bản chất. Sơ đồ dưới đây so sánh hai mô hình:
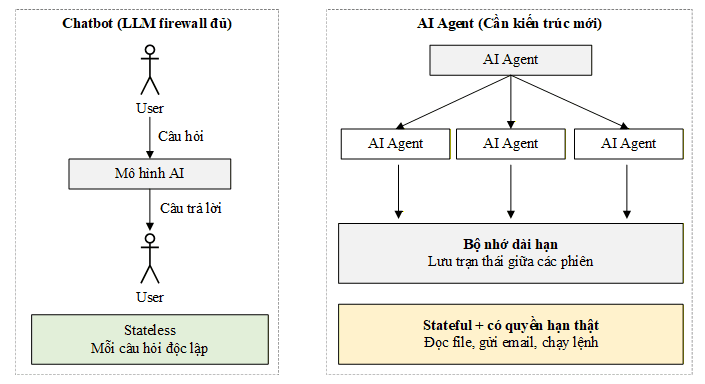
Sự khác biệt giữa chatbot và AI agent không chỉ là vấn đề tính năng mà là sự thay đổi hoàn toàn về bản chất vận hành.
Ở mô hình chatbot, mọi thứ diễn ra theo một chiều đơn giản: người dùng đặt câu hỏi, AI tạo ra câu trả lời, và vòng tương tác kết thúc tại đó. Mỗi câu hỏi là một sự kiện độc lập, hệ thống không cần nhớ gì từ lần trước, và AI thực chất không làm gì ngoài việc tạo ra văn bản. Vì toàn bộ mối đe dọa đến từ câu hỏi của người dùng, LLM Firewall chỉ cần đứng ở một điểm duy nhất để lọc là đủ.
AI agent hoạt động theo cách hoàn toàn khác. Thay vì chờ người dùng hỏi rồi trả lời, agent chủ động gọi công cụ bên ngoài, truy vấn API, đọc và ghi dữ liệu, thậm chí phối hợp với các agent khác trong cùng hệ thống. Quan trọng hơn, agent có bộ nhớ kéo dài qua nhiều phiên làm việc, nghĩa là những gì xảy ra hôm nay có thể ảnh hưởng đến hành vi của nó vào ngày mai. Và không giống chatbot chỉ tạo ra văn bản, agent có quyền hạn thực sự trong hệ thống: đọc file, gửi email, chạy lệnh, gọi API với dữ liệu thật.
Chính sự mở rộng quyền hạn và trạng thái này làm thay đổi hoàn toàn bề mặt tấn công. Kẻ tấn công không còn cần gõ lệnh độc hại trực tiếp vào ô chat nữa. Thay vào đó, chúng có thể chèn lệnh ẩn vào email, tài liệu, hoặc bản ghi cơ sở dữ liệu mà agent sẽ đọc trong quá trình làm việc. Chúng có thể đầu độc bộ nhớ dài hạn của agent để ảnh hưởng đến mọi phiên làm việc về sau. Và vì tất cả những hành động này diễn ra bên trong chuỗi hoạt động của agent chứ không phải trong câu hỏi của người dùng, LLM Firewall đứng ở đầu vào và đầu ra đơn giản là không nhìn thấy chúng.
Ba kiểu tấn công mà LLM Firewall không thấy được
Khi bài toán thay đổi như vậy, công cụ thiết kế cho bài toán cũ trở nên bất lực. Sơ đồ dưới đây minh họa ba kiểu tấn công mới mà LLM Firewall không thể phát hiện:
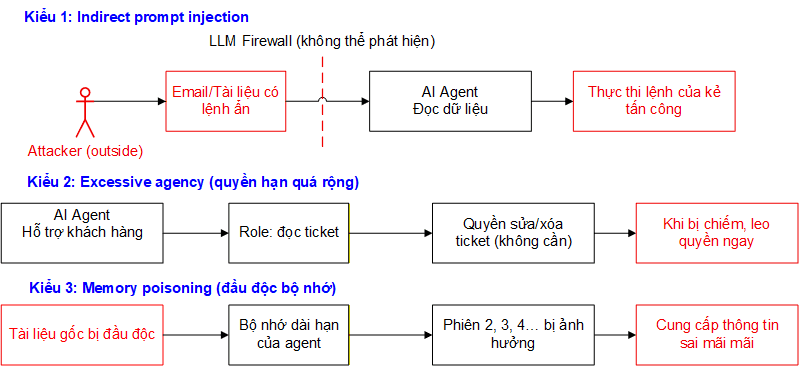
Điểm chung của cả ba kiểu tấn công. Không có gì "trông nguy hiểm" từ góc nhìn của LLM Firewall mọi thứ đều hợp lệ. LLM Firewall chỉ thấy: câu hỏi của người dùng, câu trả lời của AI, Một lần stateless, toàn bộ các actions để thao túng đều cso thể né tránh LLM firewall: dữ liệu agent đọc từ bên ngoài, tool calls và quyền hạn thực thi, bộ nhớ bị đầu độc từ phiên trước.
Trong kịch bản chatbot, kẻ tấn công phải trực tiếp gõ câu hỏi độc hại. Tường lửa thấy câu hỏi đó và chặn lại. Trong kịch bản agent, kẻ tấn công không cần tương tác trực tiếp. Chúng chèn lệnh ẩn vào những thứ mà agent sẽ đọc trong quá trình làm việc: email từ khách hàng, tài liệu trong hệ thống lưu trữ, bản ghi trong cơ sở dữ liệu. Khi agent đọc những dữ liệu đó, nó vô tình nhận lệnh từ kẻ tấn công mà không ai hay biết.
Một lỗ hổng thực tế đã được phát hiện trong hệ thống Salesforce Agentforce: agent xử lý dữ liệu khách hàng đầu vào bị điều khiển thông qua các lệnh ẩn trong chính dữ liệu đó, dẫn đến việc thông tin nội bộ bị gửi ra ngoài. Điểm CVSS đánh giá mức độ nghiêm trọng là 9.4 trên thang 10.
OWASP xác nhận: 9 trong 10 mối đe dọa nằm ngoài tầm bảo vệ
Tháng 12 năm 2025, OWASP công bố danh sách Top 10 rủi ro đầu tiên dành riêng cho các ứng dụng agent. Sơ đồ dưới đây cho thấy LLM Firewall bảo vệ được bao nhiêu trong số đó
OWASP ASI Top 10 cho agent | LLM Firewall bảo vệ được? |
| ASI01 — Prompt injection trực tiếp từ người dùng | Có, một phần (nếu từ người dùng) |
| ASI02 — Indirect prompt injection qua dữ liệu | Không |
| ASI03 — Excessive agency và leo quyền | Không |
| ASI04 — Memory poisoning | Không |
| ASI05 — Tool và plugin không an toàn | Không |
| ASI06 — Tấn công chuỗi agent | Không |
| ASI07 — Rò rỉ dữ liệu qua tool calls | Không |
| ASI08 — Giả mạo agent trong hệ thống đa agent | Không |
| ASI09 + ASI10 — Thiếu audit trail và human-in-loop | Không |
| Tổng phủ | 10% (1/10 mối đe dọa, và chỉ một phần) |
LLM Firewall bảo vệ tốt nhất một phần của ASI01. Chín mối đe dọa còn lại đòi hỏi một kiến trúc bảo mật hoàn toàn khác.
Hướng đi mới: Agent Runtime Security
Thay vì một proxy lọc văn bản, thế hệ bảo mật AI tiếp theo xây dựng trên bốn trụ cột. Sơ đồ dưới đây so sánh kiến trúc cũ và mới:
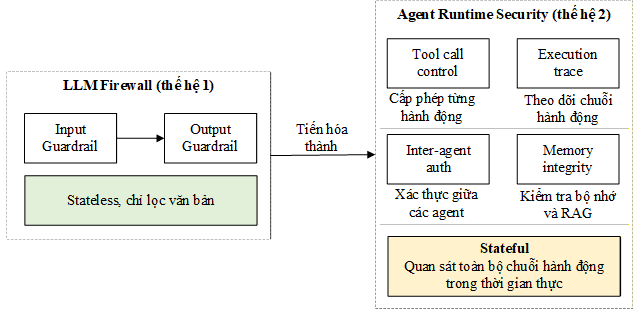
Agent Runtime Security xây dựng trên bốn trụ cột, mỗi trụ cột giải quyết một lỗ hổng mà LLM Firewall thế hệ đầu bỏ ngỏ hoàn toàn.
Trụ cột đầu tiên là kiểm soát tool calls. Mỗi lần agent muốn gọi một công cụ bên ngoài, dù là đọc file, gọi API hay chạy lệnh, hành động đó phải được kiểm tra và cấp phép riêng lẻ trước khi được thực thi. Đây là cách tiếp cận tương tự IAM và sandbox trong bảo mật truyền thống: không có hành động nào được mặc định cho phép, mọi thứ phải được xét duyệt theo từng trường hợp cụ thể.
Trụ cột thứ hai là giám sát chuỗi hành động. Thay vì chỉ ghi lại từng câu hỏi và câu trả lời riêng lẻ, hệ thống phải theo dõi và phân tích toàn bộ chuỗi suy luận và hành động của agent qua nhiều bước. Trong bảo mật hệ thống phân tán, đây là bài toán tương đương với distributed tracing trong microservices: cần nhìn thấy toàn bộ luồng thực thi, không phải từng điểm riêng rẽ.
Trụ cột thứ ba là xác thực giữa các agent. Trong hệ thống có nhiều agent phối hợp với nhau, mỗi agent phải có khả năng chứng minh danh tính với agent khác trước khi nhận lệnh hoặc chia sẻ dữ liệu. Nếu không có cơ chế này, kẻ tấn công có thể giả mạo một agent đáng tin cậy để phát lệnh độc hại xuống toàn bộ chuỗi. Tương đương trong bảo mật truyền thống là Mutual TLS và mô hình zero-trust giữa các service.
Trụ cột thứ tư là bảo vệ bộ nhớ và RAG. Trước khi bất kỳ dữ liệu nào từ bộ nhớ dài hạn hay kho kiến thức được đưa vào ngữ cảnh của agent, tính toàn vẹn của dữ liệu đó phải được kiểm tra. Một agent đọc ngữ cảnh bị đầu độc sẽ đưa ra quyết định sai mà không hề hay biết, dù bản thân mô hình AI hoàn toàn bình thường. Đây là bài toán tương đương với data integrity check trước khi đưa dữ liệu vào pipeline xử lý.
Những gì vẫn còn giá trị từ thế hệ cũ
Dù đã lỗi thời so với yêu cầu của thế giới agent, LLM Firewall thế hệ đầu không phải là thứ cần vứt bỏ hoàn toàn. Nó vẫn còn giá trị thực tế ở bốn việc cụ thể:
Thứ nhất, lọc prompt injection và jailbreak trực tiếp từ người dùng vẫn cần thiết, bởi vì dù agent có phổ biến đến đâu, kịch bản người dùng cố tình gõ lệnh độc hại vào giao diện chat vẫn tồn tại song song và không biến mất.
Thứ hai, che giấu dữ liệu cá nhân trước khi câu hỏi được gửi lên mô hình AI trên đám mây là yêu cầu đến từ luật bảo vệ dữ liệu, không phụ thuộc vào việc hệ thống đang dùng chatbot hay agent.
Thứ ba, kiểm soát nội dung không phù hợp là tầng bảo vệ nằm ở tầng ứng dụng, hoạt động độc lập với kiến trúc bên dưới.
Thứ tư, ghi log toàn bộ tương tác với AI phục vụ kiểm tra tuân thủ và kiểm toán là yêu cầu pháp lý mà hầu hết tổ chức không thể bỏ qua, bất kể công nghệ AI đang dùng là gì.
Vấn đề không nằm ở chỗ bốn việc này không có giá trị. Vấn đề nằm ở chỗ nhiều tổ chức triển khai xong LLM Firewall, nhìn thấy bốn lớp bảo vệ đó, rồi kết luận rằng mình đã đủ an toàn. Trong khi thực tế, đây chỉ là tầng bảo vệ cơ bản nhất, và toàn bộ các mối đe dọa đặc thù của agent vẫn đang hoàn toàn bỏ ngỏ phía sau.
Câu hỏi để đánh giá một công cụ bảo mật AI
Khi một tổ chức đang triển khai AI agent trong môi trường thực tế và cần chọn công cụ bảo mật, có bốn câu hỏi cần đặt thẳng cho nhà cung cấp trước khi quyết định.
Câu hỏi đầu tiên là hệ thống có kiểm tra và cấp phép từng tool call riêng lẻ không, hay chỉ dừng lại ở lọc văn bản. Đây là câu hỏi phân loại cơ bản nhất: một công cụ chỉ lọc văn bản đầu vào và đầu ra thì về bản chất không nhìn thấy những gì agent thực sự làm bên trong hệ thống, và do đó không bảo vệ được.
Câu hỏi thứ hai là hệ thống có hỗ trợ giám sát chuỗi hành động qua nhiều bước không. Indirect prompt injection, tức là tấn công qua dữ liệu mà agent đọc từ bên ngoài, chỉ có thể bị phát hiện khi nhìn vào toàn bộ chuỗi hành động chứ không phải từng bước riêng lẻ. Công cụ nào không có khả năng này thì loại tấn công phổ biến nhất với agent sẽ đi qua mà không bị chặn.
Câu hỏi thứ ba là có cơ chế xác thực giữa các agent trong hệ thống đa agent không. Trong kiến trúc nhiều agent phối hợp với nhau, nếu không có xác thực thì không có gì ngăn kẻ tấn công giả mạo một agent đáng tin cậy và phát lệnh độc hại xuống toàn bộ chuỗi bên dưới.
Câu hỏi thứ tư là có thể tạo execution trace đầy đủ để điều tra sự cố sau khi xảy ra không. Khi một agent bị tấn công thành công, câu hỏi tiếp theo luôn là nó đã làm gì, gọi công cụ nào, nhận dữ liệu gì từ đâu. Không có execution trace thì không có câu trả lời, và không có câu trả lời thì không thể đánh giá mức độ thiệt hại hay ngăn chặn tái diễn.
Nếu câu trả lời cho cả bốn câu hỏi đều là không, công cụ đó được thiết kế cho bài toán của năm 2024 và không đủ năng lực cho môi trường agent của năm 2026. Điều đó không có nghĩa là nó vô dụng, nhưng có nghĩa là đang dùng nó như một giải pháp đầy đủ thì là đang tự để ngỏ phần lớn bề mặt tấn công thực sự.
Kết luận
LLM Firewall không phải là sản phẩm tệ. Nó là sản phẩm đúng cho đúng thời điểm, nhưng thời điểm đó đã qua.
Tương tự như tường lửa lọc gói tin thế hệ đầu không biến mất khi NGFW ra đời, nhưng không ai kỳ vọng nó bảo vệ được trước các mối đe dọa hiện đại. LLM Firewall giờ đây ở vị trí tương tự: vẫn hữu ích như một lớp bảo vệ cơ bản, nhưng không đủ như một giải pháp toàn diện cho hệ thống AI agent.
Thị trường đã nhận ra điều này. Meta, NVIDIA, Radware, Palo Alto Networks đều đang chuyển hướng sang Agent Runtime Security. OWASP đã công bố tiêu chuẩn mới. SecureIQLab thông báo sẽ công bố kết quả kiểm tra độc lập đầu tiên tại Black Hat USA 2026 với 32 kịch bản tấn công, bao gồm cả những kịch bản mà LLM Firewall thế hệ đầu không thể xử lý.
Với bất kỳ tổ chức nào đang triển khai AI agent trong môi trường thực tế, câu hỏi không còn là "có nên bảo mật AI không" mà là "công cụ bảo mật mình đang dùng có được thiết kế cho đúng bài toán không".