Threat Modeling : đưa tư duy đối kháng vào thiết kế phần mềm từ sớm
16 tháng 4, 2026Son Ngo198 lượt xem
Trong nhiều đội phát triển, bảo mật thường chỉ thực sự xuất hiện khi hệ thống đã gần xong. Đến lúc đó, các quyết định quan trọng về kiến trúc, dữ liệu, xác thực, phân quyền và tích hợp đã gần như đóng lại. Khi phát hiện rủi ro, đội ngũ chỉ còn hai lựa chọn không tốt. Một là sửa rất tốn kém. Hai là chấp nhận rủi ro và hứa sẽ xử lý sau.
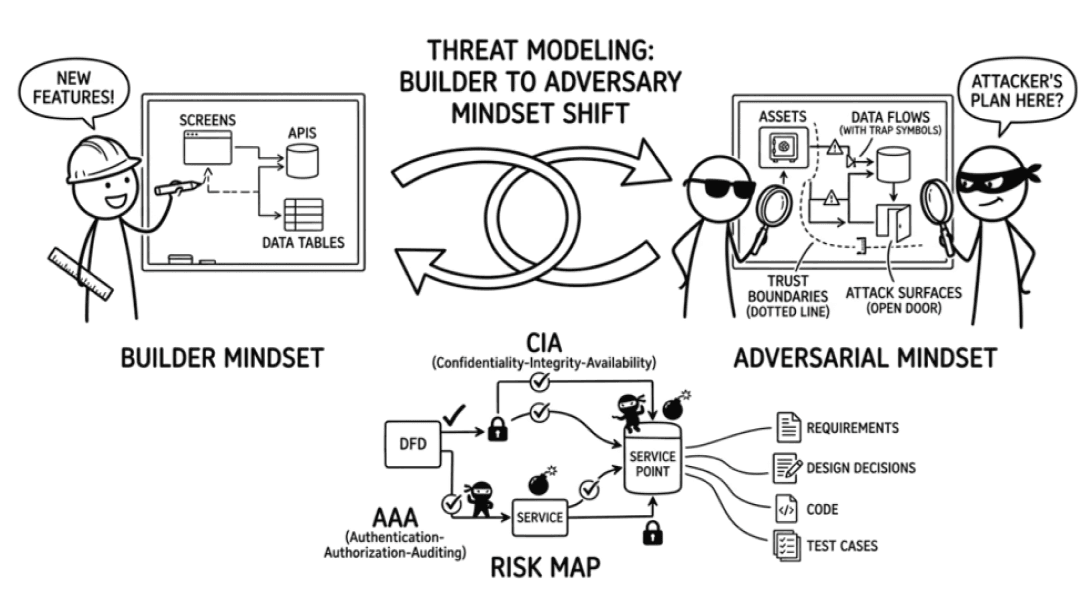
Threat Modeling, tức mô hình hóa mối đe dọa , được đặt vào giai đoạn mô hình hóa như một cách bẻ hướng toàn bộ câu chuyện đó. Hình dưới cho thấy nó không phải phần phụ được gắn thêm vào cuối dự án, mà là một lớp suy luận chen vào đúng lúc nhóm đang chuyển từ use case, kiến trúc và giao diện sang thiết kế có khả năng phòng thủ.
Điều quan trọng nhất của Threat Modeling không nằm ở chỗ nó tạo ra thêm một sơ đồ. Giá trị thật của nó là buộc nhóm ngừng hỏi hệ thống phải làm gì và bắt đầu hỏi hệ thống có thể bị lợi dụng như thế nào. Khi câu hỏi thay đổi, thiết kế cũng thay đổi.
Hình 1: Vị trí của Threat Modeling trong software modeling phase
Threat Modeling bắt đầu từ thay đổi góc nhìn
Khi nói đến việc bảo vệ một hệ thống phần mềm, nhiều đội ngũ thường nghĩ ngay đến an toàn thông tin (security). Tuy nhiên, chỉ nhìn hệ thống qua lăng kính security là chưa đủ. Một hệ thống tốt phải đồng thời giải quyết cả quyền riêng tư (privacy) và tư duy đối kháng (adversarial perspective), vì ba lớp này luôn gắn với nhau trong thực tế vận hành.
Security tập trung vào câu hỏi dữ liệu và dịch vụ có đang được bảo vệ đúng cách hay không. Dữ liệu có thể bị lộ ra ngoài, bị sửa trái phép, bị phá hỏng, hoặc hệ thống có thể bị làm gián đoạn. Privacy đi xa hơn một bước. Nó buộc đội ngũ phải trả lời những câu hỏi nền tảng hơn như hệ thống thực sự cần thu thập dữ liệu nào, dữ liệu đó được dùng cho mục đích gì, phải lưu giữ trong bao lâu, ai được phép truy cập, và khi nào cần xóa bỏ. Vì vậy, một hệ thống không thể được xem là an toàn chỉ vì nó mã hóa dữ liệu tốt. Nếu nó thu thập quá nhiều thông tin, giữ dữ liệu quá lâu, hoặc thiếu minh bạch với người dùng, thì privacy vẫn đang bị vi phạm. Ở chiều ngược lại, một hệ thống có chính sách privacy đầy đủ trên tài liệu nhưng thiếu kiểm soát kỹ thuật phù hợp thì rủi ro rò rỉ dữ liệu vẫn hoàn toàn có thể xảy ra.
Điểm kết nối giữa security và privacy nằm ở adversarial perspective. Đây là cách nhìn hệ thống từ phía những thực thể không hành xử theo kịch bản mà đội phát triển mong đợi. Đó có thể là kẻ tấn công bên ngoài, người dùng tò mò, nhân sự nội bộ, đối tác tích hợp, bot tự động, hoặc đơn giản chỉ là dữ liệu đầu vào xấu đi qua một giao diện thiếu chặt chẽ. Khi quan sát hệ thống theo hướng này, nhóm phát triển sẽ nhận ra rằng phần lớn sự cố nghiêm trọng không xuất phát từ một lỗi đơn lẻ. Chúng thường hình thành từ nhiều sai sót nhỏ, mỗi sai sót có vẻ không quá nghiêm trọng nếu đứng riêng, nhưng khi nối lại thành chuỗi thì lại mở ra một đường tấn công xuyên suốt hệ thống.
Chính vì vậy, Threat Modeling không nên bị xem là công việc riêng của đội bảo mật. Đây là một kỹ thuật suy luận cần thiết cho mọi vai trò tham gia xây dựng và vận hành sản phẩm. Kiến trúc sư cần nó để nhìn ra các ranh giới tin cậy và các điểm giao tiếp nhạy cảm. Lập trình viên cần nó để hiểu chỗ nào phải kiểm tra dữ liệu, chỗ nào phải giới hạn quyền, chỗ nào phải ghi nhận audit. QA cần nó để thiết kế các kịch bản kiểm thử vượt ra ngoài luồng sử dụng bình thường. Đội vận hành cần nó để xác định vị trí quan sát, cảnh báo và phản ứng. Khi Threat Modeling được áp dụng đúng, hệ thống không chỉ được thiết kế để chạy đúng, mà còn được thiết kế để chống chịu tốt hơn trước các rủi ro thực tế.
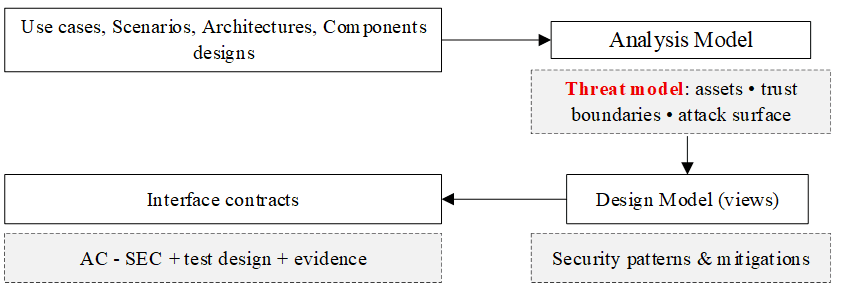
Threat Modeling càng sớm càng rẻ
Một trong những lập luận mạnh nhất của chương là Threat Modeling nên bắt đầu sớm. Nếu nhận diện mối đe dọa khi mã đã xong, database đã có dữ liệu thật và pipeline đã chạy ổn định, chi phí sửa đổi sẽ tăng rất nhanh. Khi đó, rủi ro không còn là một giả thuyết thiết kế mà đã hóa thành nợ kỹ thuật, nợ vận hành và đôi khi là nợ tuân thủ. Hình 2 làm rõ logic này. Khi threat được phát hiện trong pha mô hình hóa, phần lớn thay đổi vẫn nằm ở mức sơ đồ, hợp đồng giao diện, quy tắc xác thực hoặc phân rã thành phần. Những thay đổi đó rẻ hơn rất nhiều so với việc vá logic sau khi đã triển khai.
Hình 2: Threat Modeling như biện pháp giảm thiểu sớm trong Secure SDLC.
Một giá trị khác của Threat Modeling là tạo định hướng cho các hoạt động tiếp theo. Khi threat model đã rõ, nhóm biết nên ưu tiên tài sản nào, siết giao diện nào, kiểm thử kịch bản nào, chốt Bug Bar ở đâu và cần chuẩn bị bằng chứng gì cho Secure Design Review, tức rà soát thiết kế an toàn (Secure Design Review, SDR).
Bốn câu hỏi biến thảo luận bảo mật thành quy trình
Điểm mạnh của cách tiếp cận này là không biến Threat Modeling thành một danh sách kỹ thuật rời rạc. Thay vào đó, toàn bộ hoạt động được quy về bốn câu hỏi ngắn gọn nhưng đủ chiều sâu:
Q1 - Chúng ta đang xây dựng cái gì?
Q2 - Điều gì có thể đi sai hướng?
Q3 - Chúng ta sẽ làm gì để xử lý?
Q4 - Chúng ta đã làm tốt chưa?
Bốn câu hỏi này tạo thành một vòng lặp suy luận rõ ràng. Câu hỏi đầu tiên buộc nhóm phải dựng lại bối cảnh hệ thống, hiểu thành phần nào đang tồn tại, dữ liệu đi qua đâu, ai tương tác với ai và đâu là các ranh giới quan trọng. Câu hỏi thứ hai đẩy cả nhóm sang góc nhìn đối kháng, từ đó nhìn ra những khả năng sai hỏng, lạm dụng hoặc tấn công mà luồng sử dụng bình thường thường che khuất. Câu hỏi thứ ba biến phần nhận diện rủi ro thành quyết định giảm thiểu cụ thể. Câu hỏi cuối cùng buộc mọi quyết định phải đi đến kiểm chứng, bằng chứng và đánh giá lại mức rủi ro còn sót lại.
Chính cấu trúc này làm cho Threat Modeling trở nên thực dụng và dễ áp dụng trong dự án thật. Nhóm không cần bắt đầu bằng một hệ phân loại quá nặng nề. Điều quan trọng hơn là trả lời lần lượt bốn câu hỏi và bảo đảm rằng mỗi câu trả lời đều để lại các sản phẩm đầu ra (artifacts) đủ dùng, chẳng hạn như sơ đồ ngữ cảnh (context diagram), sơ đồ luồng dữ liệu (Data Flow Diagram, DFD), danh sách tài sản (asset list), danh sách mối đe dọa (threat list), bảng rủi ro (risk table), kế hoạch giảm thiểu (mitigation plan) và các ý tưởng kiểm thử (test ideas). Khi đó, Threat Modeling không còn là một buổi thảo luận mang tính hình thức, mà trở thành một phần có thể truy vết, kiểm chứng và tái sử dụng trong toàn bộ vòng đời phát triển phần mềm.
Đừng nói về rủi ro khi chưa biết mình đang bảo vệ cái gì
Q1, tức câu hỏi chúng ta đang xây dựng cái gì, là điểm mở đầu nhưng cũng là nơi nhiều nhóm làm qua loa nhất. Họ thường lao ngay vào việc kể tên lỗ hổng mà chưa dựng rõ phạm vi hệ thống, tác nhân tham gia, loại dữ liệu đang đi qua và nơi niềm tin thay đổi. Khi thiếu lớp nền này, Threat Modeling rất dễ biến thành một danh sách chung chung, hệ thống nào đọc vào cũng thấy giống nhau.
Một cách làm chặt chẽ hơn là bắt đầu từ bốn thành phần nền tảng gồm tài sản (asset), bề mặt tấn công (attack surface), điểm đầu vào (entry point) và ranh giới tin cậy (trust boundary). Asset trả lời câu hỏi cái gì thực sự đáng được bảo vệ. Attack surface cho biết từ bên ngoài người ta có thể chạm vào hệ thống ở đâu. Entry point thu hẹp tiếp xuống từng cánh cửa cụ thể mà dữ liệu, lệnh gọi hoặc yêu cầu đi vào. Trust boundary cho biết nơi mức độ tin cậy thay đổi, vì vậy cũng chính là nơi dữ liệu, danh tính và quyền truy cập phải được kiểm tra lại. Đây là bộ khung giúp Q1 không còn là một câu hỏi mơ hồ, mà trở thành một hoạt động dựng bản đồ hệ thống có thể kiểm tra được.
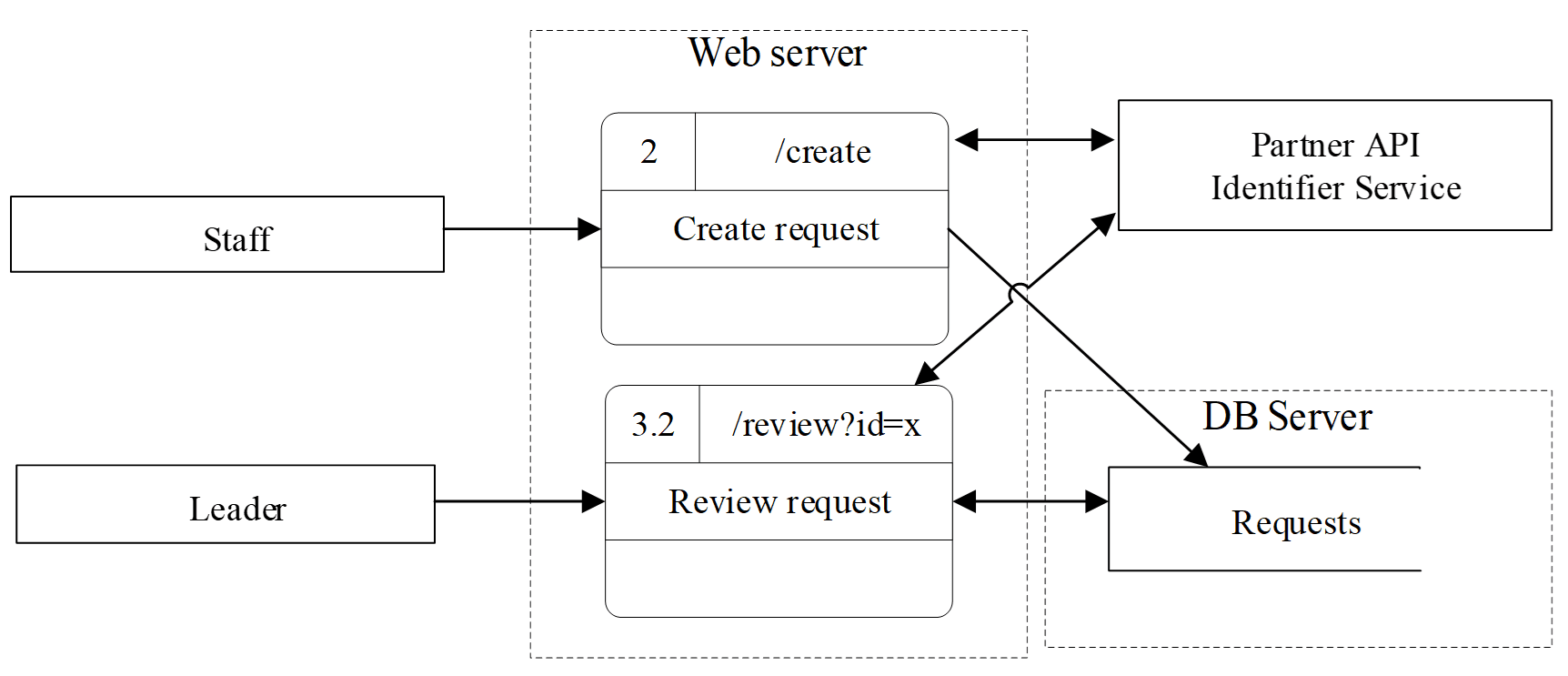
Hình 3 bên dưới đặc biệt hữu ích vì nó đưa toàn bộ tư duy trên vào một sơ đồ luồng dữ liệu (Data Flow Diagram, DFD) ở mức sơ bộ, có trust boundaries và entry points đi kèm. Chỉ cần nhìn vào các luồng giữa client, web server, service và kho dữ liệu trong hình, nhóm đã có thể đặt ra các câu hỏi đúng bản chất như dữ liệu nào đang đi qua boundary nào, thành phần nào được phép gọi thành phần nào, và tại điểm nào cần áp dụng xác thực (Authentication, AuthN), phân quyền (Authorization, AuthZ), kiểm tra dữ liệu đầu vào (validation) và ghi vết kiểm toán (audit). Chính sơ đồ kiểu này làm cho Q1 trở thành một bước khảo sát kiến trúc thực dụng, thay vì một buổi thảo luận cảm tính.
Hình 3: Sơ bộ DFD-0/DFD-1 với trust boundaries và entry points.
Để Threat Model đầy đủ, cần nhận diện các ranh giới tin cậy (trust boundaries), tức những nơi mức độ trust thay đổi rõ rệt. Mỗi khi dữ liệu đi qua một trust boundary, nó phải được xem là chưa đáng tin cho đến khi được xác minh. Các ví dụ điển hình gồm ranh giới từ Internet vào lớp biên (Internet → Edge/DMZ), từ frontend sang backend, từ ứng dụng sang cơ sở dữ liệu (App → DB), và từ hệ thống nội bộ sang giao diện lập trình ứng dụng của đối tác (Partner API).
Trust boundary không chỉ là khái niệm logic mà thường gắn trực tiếp với chi tiết triển khai. Một request từ trình duyệt vào backend, một truy vấn từ service xuống database, hay một cuộc gọi ra bên thứ ba đều là những điểm mà trust thay đổi. Vì vậy, mỗi đường đi như vậy phải có giao diện hoặc giao thức rõ ràng, có kiểm soát phù hợp, và có khả năng ghi vết.
Nguyên tắc quan trọng là luôn băng qua trust boundary bằng interface hoặc protocol rõ ràng, đồng thời giảm tối đa các tác dụng phụ ngoài kiểm soát. Những đường tắt như script truy cập thẳng database, chia sẻ tệp nội bộ để gọi chéo chức năng, hoặc sửa trực tiếp trong container đều làm phá vỡ trust boundary và khiến Threat Model mất giá trị.
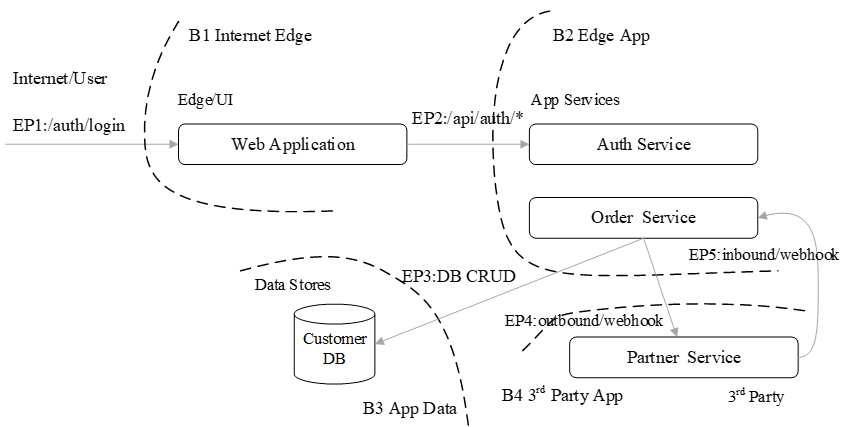
Hình 4: Ví dụ về trust boundaries và data flows giữa các services.
Như Hình 4 minh họa, các đường B1 đến B4 là các trust boundaries, còn EP1 đến EP5 là các điểm vào (entry points) băng qua từng ranh giới. Cách mô hình hóa này giúp ta trả lời rõ mỗi khi dữ liệu nhạy cảm như PII, token hoặc secret di chuyển, nó đã đi qua những ranh giới nào, giao thức nào đang bảo vệ nó, và lớp kiểm soát nào sẽ phát hiện nếu hành vi đi lệch khỏi kịch bản mong đợi.
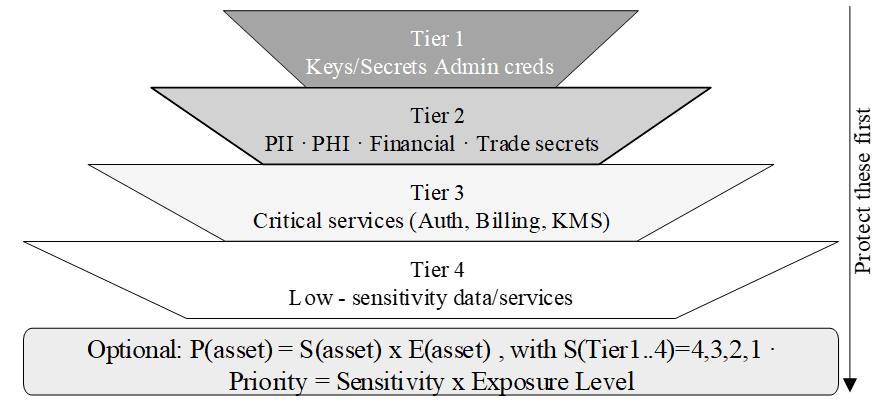
Sau khi có bản đồ ( có thể hiểu rộng là các thiết kế hệ thống) , việc tiếp theo không phải là xem mọi thứ quan trọng như nhau, mà là phân tầng tài sản. Bảng 1 trình bày danh sách tài sản (asset register) tối thiểu nên ghi được tên tài sản, loại, danh mục dữ liệu, owner, sensitivity, cấp độ, location và retention. Với cách nhìn đó, nhóm không chỉ biết mình có gì, mà còn biết tài sản nào nhạy cảm hơn, đang nằm ở đâu và phải giữ bao lâu. Đây là nền tảng để tránh tình trạng bảo vệ dàn đều nhưng thiếu trọng tâm.
Bảng 1: Ví dụ về danh sách tài sản (asset register)
Tên tài sản
Loại
Danh mục dữ liệu
Owner
Sensitivity
Cấp độ
Location
Retention
Customer PII
Data
PII
Data Steward
High
2
DB:prod-eu-1 (PostgreSQL)
2 năm
Payment Card Data
Data
Financial (PCI)
Payments Lead
High
2
Tokenized via PSP; vault (PCI segment)
Không lưu trữ (đã token hóa)
Access Tokens
Secret
Secrets
IAM Owner
High
1
KMS-backed store
Xoay vòng mỗi 90 ngày
Signing Key
Secret
Keys/Certificates
Security
High
1
HSM
Xoay vòng hàng năm; hủy khi có sự cố
Từ danh mục đó, ta tiếp tục đẩy tư duy đi thêm một bước bằng cách xếp keys, secrets và thông tin quản trị vào tầng ưu tiên bảo vệ cao nhất, sau đó mới đến dữ liệu cá nhân, dữ liệu tài chính, các dịch vụ trọng yếu và cuối cùng là những tài sản ít nhạy cảm hơn. Cách phân tầng trong như vậy rất quan trọng vì nó nhắc đội dự án rằng không phải mọi thứ đều cần cùng một mức kiểm soát. Trong thực tế, nếu coi mọi nơi đều quan trọng như nhau thì hệ quả thường là nơi thật sự nguy hiểm lại không được bảo vệ đủ mạnh. Ưu tiên đúng tài sản vì thế là điều kiện để ưu tiên đúng kiểm soát.
Hình 5: Các tầng tài sản và ưu tiên bảo vệ.
Nếu ghép Bảng 1 với Hình 3,4,5 (cùng với các bản thiết kế khác nữa), Q1 sẽ không còn là câu hỏi mang tính hình thức. Nó trở thành bước dựng bản đồ bảo vệ của hệ thống: biết cái gì đáng giữ, biết kẻ khác có thể đi vào từ đâu, biết dữ liệu băng qua những ranh giới nào, và biết chỗ nào phải siết kiểm soát mạnh nhất. Đó mới là nền đủ chắc để các câu hỏi tiếp theo của Threat Modeling đi tiếp mà không rơi vào nói chung chung.
Ưu tiên dựa trên rủi ro, không dựa trên cảm giác
Sau khi đã biết hệ thống là gì, Q2 và Q3 mới có nền để làm việc. Q2 hỏi điều gì có thể đi sai hướng. Q3 hỏi chúng ta sẽ làm gì để xử lý. Hai câu hỏi này được nối với nhau bằng tư duy ưu tiên theo Likelihood × Impact.
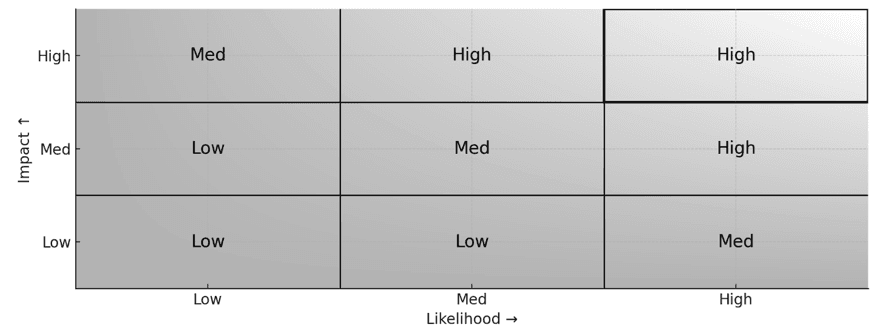
Hình 6 minh họa bản đồ nhiệt rủi ro rất trực quan. Không phải threat nào cũng đáng xử lý với cùng một mức đầu tư. Những gì nằm trên high value assets, đi qua entry point công khai và có khả năng bị khai thác thường xuyên phải được ưu tiên trước. Ngược lại, một rủi ro có impact thấp và exposure thấp có thể được chấp nhận tạm thời nếu đã ghi nhận rõ residual risk, tức rủi ro còn lại.
Hình 6 Bản đồ nhiệt rủi ro Likelihood × Impact.
Điểm đáng chú ý là chương không xem việc ưu tiên rủi ro như một thao tác hành chính. Nó gắn trực tiếp với kiến trúc và kiểm soát. Khi đánh giá likelihood tăng vì endpoint đang public, nhóm có thể giảm likelihood bằng rate limiting, hardening đầu vào, ký request, tách boundary hoặc giảm đặc quyền. Khi impact cao vì asset ở mức Tier 1 hoặc Tier 2, nhóm phải nghĩ đến isolation, mã hóa, logging bất biến và cơ chế khôi phục.
Rà soát và bằng chứng cho rủi ro còn lại
Câu hỏi thứ tư không đơn thuần là bước kết thúc của một vòng Threat Modeling. Nó là thời điểm nhóm dừng lại để nhìn lại toàn bộ chuỗi quyết định một cách cẩn thận, đặc biệt với những quyết định đã được hình thành từ nhiều kinh nghiệm thực chiến, giả định thiết kế và sự đánh đổi về nguồn lực. Ở đây, vấn đề không còn là nghĩ thêm mối đe dọa nào nữa, mà là kiểm tra xem những gì nhóm đã chọn làm có thực sự đủ chắc hay chưa. Q4 vì thế tập trung vào hai việc. Thứ nhất là xác định rủi ro còn lại (residual risk) sau khi đã áp dụng các biện pháp giảm thiểu. Thứ hai là kiểm tra xem có bằng chứng nào cho thấy các quyết định ở bước trước đã được thực hiện thật, có hiệu lực thật, và đang được theo dõi đến cùng hay không.
Điểm quan trọng của Q4 là nó buộc nhóm phải chuyển từ niềm tin sang kiểm chứng. Một biện pháp giảm thiểu không thể chỉ tồn tại dưới dạng ý tưởng hợp lý trên giấy. Nó phải để lại dấu vết có thể xem xét được, chẳng hạn qua code review, rà soát luồng xử lý, kiểm thử bảo mật, hoặc bằng chứng cấu hình trên môi trường triển khai. Nếu một biện pháp chưa làm, làm một phần, hoặc cố ý trì hoãn, điều đó cũng phải được ghi lại minh bạch cùng với lý do, điều kiện chấp nhận và cách theo dõi tiếp theo. Chính chỗ này cho thấy kinh nghiệm là rất quan trọng, vì nhiều quyết định an toàn không phải lúc nào cũng có câu trả lời tuyệt đối đúng sai. Chúng thường dựa trên hiểu biết tích lũy về hệ thống, về kiểu sai hỏng thường gặp, về khả năng vận hành thực tế và về mức rủi ro mà tổ chức có thể chấp nhận. Nhưng dù quyết định dựa nhiều vào kinh nghiệm, Q4 vẫn yêu cầu kinh nghiệm đó phải được neo vào bằng chứng và trách nhiệm theo dõi rõ ràng.
Q4 cũng là nơi nhóm rà lại độ đầy đủ của toàn bộ bức tranh. Nhóm cần xem các tài sản giá trị cao đã được bao phủ đủ chưa, các ranh giới tin cậy (trust boundary) đã được xem xét hết chưa, và các giả định quan trọng về phạm vi hay môi trường vận hành có đang còn đúng không. Đây là bước rất dễ bị bỏ qua, trong khi trên thực tế chỉ cần một giả định sai thì toàn bộ đánh giá phía trước có thể lệch hướng. Vì vậy, Q4 không chỉ nhìn vào từng biện pháp riêng lẻ mà còn nhìn vào sự nhất quán của toàn bộ mô hình rủi ro. Nó là bước rà soát tỉnh táo, nơi nhóm tự hỏi liệu còn điểm mù nào chưa thấy, còn khoảng trống nào chưa khóa, và còn quyết định nào đang được chấp nhận theo thói quen hơn là theo bằng chứng hay không.
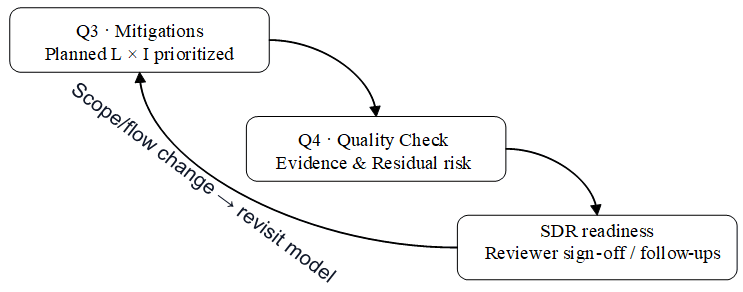
Hình 7 Vòng phản hồi từ các biện pháp giảm thiểu đến sự sẵn sàng SDR.
Nếu nhìn theo quy trình, Q4 chính là điểm nối từ suy luận sang quản trị. Hình 7 mô tả rõ vòng phản hồi từ các biện pháp giảm thiểu đến trạng thái sẵn sàng cho rà soát thiết kế an toàn (Secure Design Review, SDR). Sau khi nhóm lập kế hoạch xử lý ở bước trước, Q4 kiểm tra lại chất lượng quyết định bằng residual risk và evidence, rồi đưa kết quả đó sang trạng thái sẵn sàng cho SDR. Đồng thời, mũi tên phản hồi trong Hình 7 cũng nhắc rằng đây không phải điểm đóng vĩnh viễn. Mỗi thay đổi lớn của hệ thống, mỗi lần review quan trọng, hoặc mỗi phát hiện mới đều có thể kích hoạt một vòng Threat Modeling mới. Nói cách khác, Q4 biến một buổi workshop thành một dòng công việc có kiểm soát, có follow up, và có khả năng học lại từ chính kinh nghiệm của nhóm để điều chỉnh vòng lặp tiếp theo cho chắc hơn.
STRIDE là taxonomy để suy nghĩ có cấu trúc, không phải checklist máy móc
Ở các mục trước, chúng ta đã dựng xong bộ khung của hệ thống: biết mình đang bảo vệ những tài sản nào, bề mặt tấn công gồm những điểm thâm nhập nào, và dữ liệu đang băng qua những ranh giới tin cậy nào. 4 câu hỏi đã giúp ta đặt đúng chuỗi câu hỏi từ Q1 tới Q4, nhưng vẫn còn thiếu một mảnh ghép quan trọng: một ngôn ngữ chung để đặt tên và phân loại các mối đe dọa. Nếu không có ngôn ngữ này, mỗi lần thảo luận về câu hỏi What can go wrong? rất dễ trở thành cuộc trò chuyện cảm tính, thiếu hệ thống và khó lặp lại. Trong thực hành, cộng đồng an toàn thông tin thường sử dụng STRIDE, một mô hình phân loại mối đe dọa của Microsoft. Nó được xem như một bộ chữ cái cơ bản cho mô hình hóa mối đe dọa. STRIDE không phải là một phương pháp hoàn chỉnh mà là một hệ thống phân loại gồm sáu nhóm đe dọa nhằm đảm bảo tính bao phủ:
S - Spoofing (giả mạo)
T - Tampering (sửa đổi trái phép)
R - Repudiation (chối bỏ trách nhiệm)
I - Information Disclosure (rò rỉ thông tin)
D - Denial of Service (từ chối dịch vụ)
E - Elevation of Privilege (leo thang đặc quyền)
Khi bản đồ hệ thống đã đủ rõ, STRIDE mới thật sự phát huy giá trị. Đây là một điểm rất quan trọng trong cách tiếp cận Threat Modeling. STRIDE không được dùng để thay thế hiểu biết về hệ thống, mà chỉ nên xuất hiện sau khi nhóm đã xác định được tài sản (asset), luồng dữ liệu (data flow), điểm đầu vào (entry point) và ranh giới tin cậy (trust boundary). Nếu đưa STRIDE vào quá sớm, kết quả thường chỉ là một danh sách đe dọa mang tính liệt kê, thiếu ngữ cảnh và khó chuyển thành hành động kỹ thuật cụ thể.
Giá trị lớn của STRIDE nằm ở chỗ nó cung cấp một ngôn ngữ chung để trả lời câu hỏi điều gì có thể đi sai hướng. Thay vì cố nhớ hàng loạt kịch bản tấn công rời rạc, nhóm chỉ cần đi qua từng thành phần, từng luồng dữ liệu và từng ranh giới tin cậy rồi soi chúng dưới sáu lăng kính quen thuộc của STRIDE. Cách làm này vừa đủ đơn giản để dùng trong workshop, vừa đủ chặt để giữ cho buổi phân tích không trôi sang cảm tính.
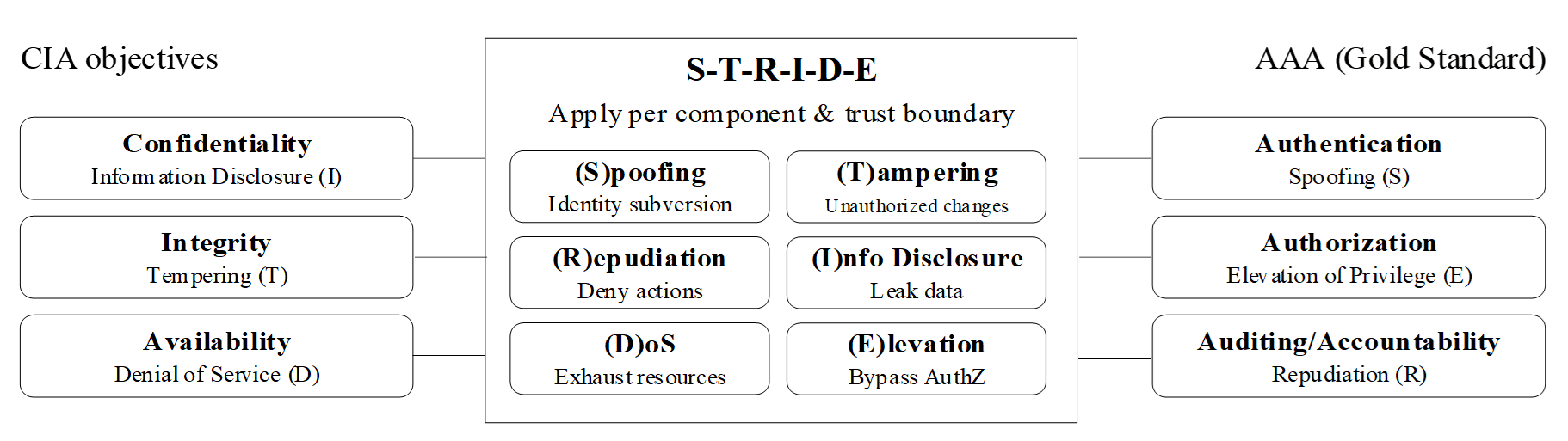
Hình 8: Ánh xạ STRIDE với CIA và AAA
Hình 8 đặc biệt hữu ích vì nó đặt STRIDE lên cùng trục với hai khung mục tiêu nền tảng là CIA và AAA. Theo cách ánh xạ này, Spoofing gắn chặt với xác thực (Authentication), Tampering gắn với tính toàn vẹn (Integrity), Repudiation gắn với kiểm toán và truy cứu trách nhiệm (Auditing and Accountability), Information Disclosure gắn với tính bảo mật (Confidentiality), Denial of Service gắn với tính sẵn sàng (Availability), còn Elevation of Privilege gắn với phân quyền (Authorization). Nhờ vậy, STRIDE không còn là sáu chữ cái mang tính ghi nhớ, mà trở thành một khung suy luận nối trực tiếp các mối đe dọa với mục tiêu bảo vệ của hệ thống.
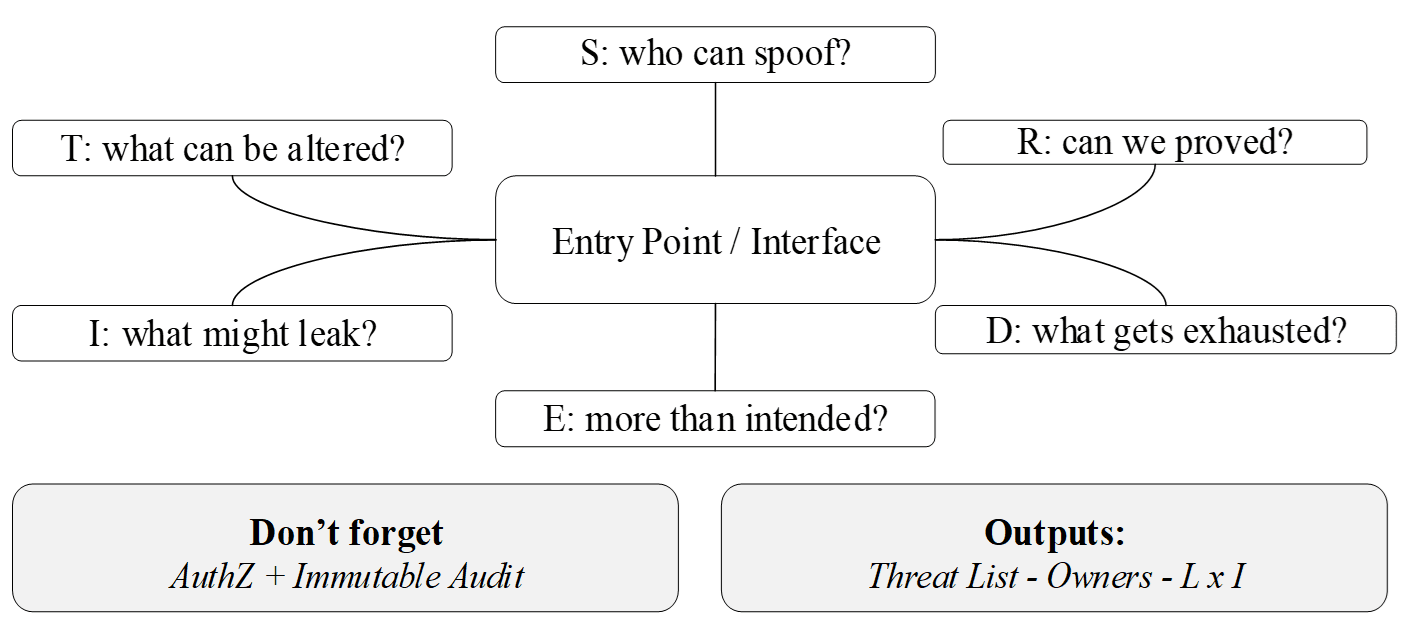
Nếu Hình 8 giúp nhóm hiểu STRIDE ở mức khái niệm, thì Hình 9 lại kéo toàn bộ khung suy luận đó xuống đúng nơi rủi ro thường bắt đầu, tức các điểm đầu vào (entry points) của hệ thống. Ở đây, mỗi entry point không còn được nhìn như một chi tiết kỹ thuật nhỏ, mà được xem như một vị trí kiểm soát, nơi dữ liệu, lệnh gọi hoặc danh tính đi từ bên ngoài vào trong hệ thống. Chính vì vậy, rà soát theo entry point thường thực tế hơn nhiều so với việc quét đều mọi thành phần ở mức quá rộng.
Hình 9: Rà soát trên các entry points.
Với mỗi entry point, nhóm có thể đặt sáu câu hỏi tương ứng với STRIDE. Ai có thể giả mạo tại điểm vào này. Điều gì có thể bị sửa trái phép khi đi qua đây. Thông tin nào có thể bị lộ ra từ phản hồi, lỗi, log hoặc metadata. Hành động nào về sau không thể chứng minh nếu thiếu audit đủ mạnh. Tài nguyên nào có thể bị làm cạn để gây từ chối dịch vụ. Và cuối cùng, có khả năng nào một tác nhân vượt quá quyền được cấp qua chính điểm vào đó hay không. Nhờ cách đặt câu hỏi như vậy, STRIDE không bị treo ở mức lý thuyết mà được ép bám sát vào nơi hệ thống tiếp xúc với thế giới bên ngoài.
Cách nhìn theo entry point cũng giúp việc ưu tiên trở nên sắc hơn. Không phải mọi giao diện đều cần cùng một mức rà soát. Những điểm vào chạm tới tài sản giá trị cao, băng qua trust boundary hoặc cho phép kích hoạt hành động nhạy cảm nên được xem xét kỹ hơn, cả về AuthN, AuthZ, validation, rate limiting, logging lẫn khả năng chịu tải. Khi làm như vậy, đội dự án sẽ tránh được tình trạng tạo ra một threat list dài nhưng mỏng, thay vào đó tập trung được vào đúng những cánh cửa mà nếu kiểm soát lỏng lẻo thì hậu quả sẽ lan rất nhanh vào sâu bên trong hệ thống. Review các entrypoints vì thế không chỉ là một minh họa, mà là một mẫu rà soát thực dụng có thể dùng lặp lại trong các buổi review thiết kế, review API và review integration.
Misuse Case là nơi Threat Modeling chạm vào nghiệp vụ
Ở các phần trước, chúng ta dùng bốn câu hỏi, STRIDE, tài sản (assets), điểm vào (entry points) và ranh giới tin cậy (trust boundary) để rà soát kiến trúc. Tuy nhiên, phần lớn các mô hình này vẫn đứng từ góc nhìn của người xây hệ thống: người dùng hợp lệ làm gì, luồng chuẩn đi ra sao, điều gì nên xảy ra. Kịch bản lạm dụng (misuse/abuse case) là phần bù còn thiếu, vì nó đảo ngược góc nhìn và mô tả chính luồng đó từ phía kẻ tấn công. Khi đặt use case và misuse case cạnh nhau, nhiều điểm yếu về phân quyền (Authorization, AuthZ), ghi vết (logging), và chống lạm dụng (anti-abuse) sẽ lộ rõ hơn.
Về bản chất, misuse case là mô tả cách một tác nhân cố ý lợi dụng một chức năng để gây hại hoặc trục lợi. Thay vì chỉ viết người dùng muốn đặt lại mật khẩu để lấy lại quyền truy cập, ta viết theo hướng attacker muốn thăm dò chức năng đặt lại mật khẩu để dò tài khoản hợp lệ. Cách viết này giữ được cấu trúc quen thuộc của user story nhưng buộc đội thiết kế phải trả lời các câu hỏi quan trọng: ai có thể lạm dụng tính năng này, họ đi vào từ entry point nào, băng qua trust boundary nào, và asset nào đang bị đe dọa.
Một misuse case thường nên có vài thành phần cốt lõi:
Câu chuyện đảo chiều (reverse user story): tác nhân độc hại muốn làm gì và muốn đạt được điều gì
Phạm vi và tài sản (scope and assets): dữ liệu cá nhân, khóa bí mật, tiền, hạn mức, ngân sách khuyến mãi, uy tín hệ thống
Điểm vào và ranh giới tin cậy (entry point and boundary crossing): endpoint cụ thể và các boundary mà luồng đi qua
Điều kiện tiên quyết (preconditions): các điểm yếu khiến tấn công khả thi như thiếu AuthZ, thông báo lỗi khác nhau, API không idempotent
Dấu hiệu phát hiện (detection criteria): tín hiệu và ngưỡng có thể đưa vào dashboard hoặc alert
Biện pháp giảm thiểu và người phụ trách (mitigations and owner): kiểm soát kỹ thuật hoặc quy trình, cùng team chịu trách nhiệm thực hiện
Tóm lại, misuse/abuse case giúp Threat Modeling bớt trừu tượng hơn bằng cách chuyển từ câu hỏi hệ thống nên hoạt động thế nào sang câu hỏi hệ thống có thể bị lợi dụng thế nào. Nhờ đó, nhóm phát triển dễ nối các rủi ro đã nhận diện với STRIDE, với detection, và với các biện pháp giảm thiểu cụ thể hơn.
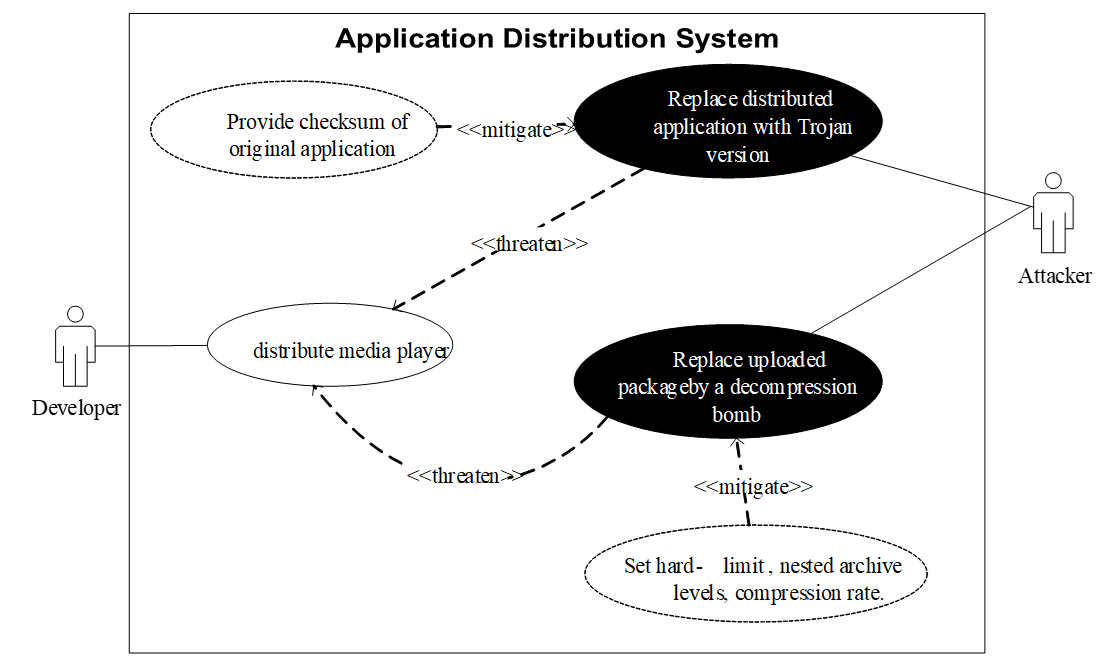
Hình 10 minh họa một bối cảnh là hệ thống phân phối ứng dụng. Ở luồng hợp lệ, nhà phát triển tải lên một ứng dụng hợp pháp để người dùng tải về và cài đặt. Nhưng khi nhìn theo misuse case, có ít nhất hai khả năng lạm dụng rõ ràng.
Hình 10: Usecase và Misuse cases trong ứng dụng hệ thống phân phối ứng dụng
Kịch bản thứ nhất là thay thế gói cài đặt hợp pháp bằng một phiên bản đã bị cài mã độc (trojanized version). Khi đó, người dùng tưởng đang tải phần mềm hợp lệ nhưng thực tế lại cài backdoor. Misuse case ở đây là attacker thay thế gói ứng dụng để chiếm quyền trên thiết bị người dùng ở quy mô lớn. Các kiểm soát phù hợp gồm checksum hoặc cryptographic hash, chữ ký số (digital signature), và kiểm soát chặt quyền upload hoặc replace.
Kịch bản thứ hai là tải lên một gói nén gây nổ giải nén (decompression bomb), tức file nhỏ khi lưu trữ nhưng phình rất lớn khi giải nén. Nếu hệ thống không giới hạn kích thước sau giải nén hoặc số tầng nén, chỉ vài package như vậy cũng có thể làm đầy đĩa, cạn bộ nhớ hoặc làm tê liệt pipeline quét. Misuse case ở đây là attacker tải lên decompression bomb để làm cạn tài nguyên và phá vỡ dịch vụ phân phối. Cách giảm thiểu là đặt giới hạn cứng về kích thước, độ sâu nén, thời gian xử lý, từ chối gói vượt ngưỡng và ghi log đầy đủ để truy vết.
Đây chính là lúc mà kỹ sư ATTT với tư duy đối kháng được rèn luyện trên ghế nhà trường sát cánh cùng đội ngũ để đảm bảo ứng dụng đã lường trước các kịch bản rủi ro ngay từ những ngày đầu tiên. Để triển khai được các giai đoạn tiếp theo như mitigations / design review / code review/ secure ci/cd những kết quả của Threat modelling là vô cùng quan trọng.
Lời Kết
Mô hình hóa mối đe dọa (Threat Modeling) thường bị xem nhầm như một tài liệu phụ thêm vào cho đầy đủ quy trình. Nhưng nếu hiểu đúng, đây chính là điểm mà bảo mật bắt đầu chuyển hóa thành các quyết định thiết kế cụ thể. Nó buộc đội ngũ phải nhìn lại hệ thống từ những yếu tố cốt lõi nhất như tài sản cần bảo vệ, các điểm đầu vào, các ranh giới tin cậy, mức độ rủi ro và cả khả năng một luồng nghiệp vụ hợp lệ bị khai thác theo hướng không hợp lệ. Quan trọng hơn, Threat Modeling không chấp nhận các lập luận bảo mật chỉ dừng ở mức ý tưởng. Mọi nhận định đều phải đi tiếp đến các biện pháp kiểm soát thực tế và các bằng chứng có thể kiểm tra được.
Có thể diễn đạt ngắn gọn rằng Threat Modeling là quá trình đặt ra những câu hỏi đúng trước khi mã nguồn làm cho các câu trả lời trở nên khó thay đổi. Càng thực hiện sớm, đội phát triển càng còn nhiều lựa chọn thiết kế. Càng làm có cấu trúc, kiến trúc càng bớt ngây thơ trước các hành vi đối kháng. Và càng gắn chặt với luồng nghiệp vụ, bảo mật càng không còn là trách nhiệm riêng của một nhóm chuyên trách, mà trở thành năng lực chung của toàn bộ đội ngũ phát triển.
Nội dung trong bài viết được trích một phần từ cuốn sách: