Nhiều đội phát triển chỉ thật sự nghĩ đến mật mã học (cryptography) khi hệ thống cần mã hóa dữ liệu, phát sinh token, ký số tài liệu, hoặc bảo vệ kênh truyền giữa các dịch vụ. Nhưng trong thực tế, đây không phải là một lớp kỹ thuật chỉ dành cho chuyên gia bảo mật. Với kỹ sư phần mềm, cryptography trước hết nên được hiểu như một bộ công cụ giúp hệ thống khó bị đọc trộm hơn, khó bị sửa lén hơn, khó bị giả mạo hơn, và dễ truy vết hơn khi sự cố xảy ra. Giá trị của nó không nằm ở sự phức tạp của công thức toán học, mà nằm ở chỗ nó giải quyết đúng những rủi ro rất cụ thể trong quá trình xây dựng và vận hành phần mềm.
Điều quan trọng là không nên nhìn cryptography như một phép màu. Nó không thể tự mình làm cho hệ thống an toàn nếu kiến trúc lỏng lẻo, quyền truy cập quá rộng, hay quy trình vận hành thiếu kỷ luật. Ngược lại, khi được đặt đúng chỗ, nó tạo ra những lớp bảo vệ rất mạnh. Chẳng hạn, nó giúp tạo ra các giá trị khó đoán để làm khóa, token hoặc mã phiên làm việc. Nó giúp kiểm tra xem dữ liệu có bị sửa giữa đường hay không. Nó giúp thiết lập kênh truyền bí mật qua môi trường không đáng tin cậy. Nó cũng giúp gắn nguồn gốc rõ ràng cho một thông điệp hay một giao dịch. Nói cách khác, cryptography không thay thế thiết kế an toàn, nhưng nó là một phần rất quan trọng để biến thiết kế an toàn thành hành vi bảo vệ thực tế của hệ thống.
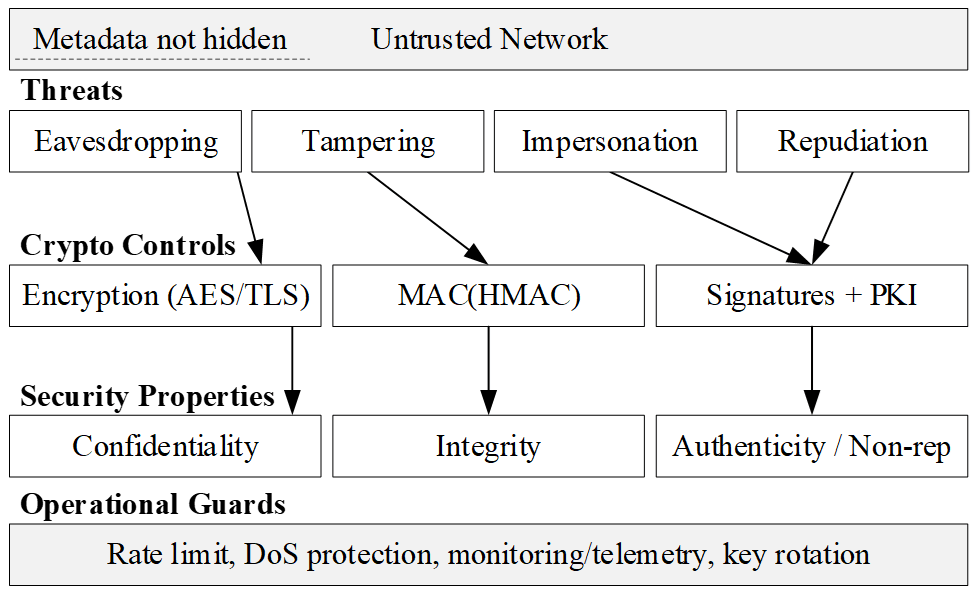
Hình 1. Mối liên hệ giữa Mối đe dọa → cơ chế mật mã → thuộc tính an ninh.
Nếu nhìn dưới góc độ kỹ thuật phần mềm, Hình 1 cho thấy một ý rất dễ hiểu. Mỗi nhóm rủi ro thường cần một nhóm cơ chế phù hợp để xử lý. Khi dữ liệu đi qua mạng công cộng hoặc một môi trường không đáng tin cậy, mã hóa giúp bảo vệ tính bí mật (confidentiality) trước hành vi nghe lén. Cơ chế kiểm tra tính hợp lệ của thông điệp giúp bảo vệ tính toàn vẹn (integrity) trước việc sửa đổi trái phép. Chữ ký số và hạ tầng khóa công khai giúp bảo vệ tính xác thực (authenticity) và hỗ trợ chống chối bỏ (non repudiation) trước hành vi giả mạo hoặc phủ nhận trách nhiệm. Hình này cũng nhắc một điều rất thực tế là mã hóa không che giấu hết mọi thứ. Ai đang nói chuyện với ai, vào lúc nào, với tần suất bao nhiêu, đôi khi vẫn có thể bị lộ qua metadata. Vì vậy cryptography luôn phải đi cùng các lớp vận hành khác như giám sát, rate limiting, xoay vòng khóa và kiểm soát truy cập.
Với kỹ sư phần mềm, trọng tâm không phải là tự xây thuật toán mới, cũng không phải là cố hiểu toàn bộ nền toán học phía sau từng kỹ thuật. Điều cần thiết hơn là biết chọn đúng công cụ chuẩn và dùng nó đúng cách. Phần lớn sự cố thực tế không đến từ việc AES, RSA hay SHA bị phá vỡ, mà đến từ cách dùng sai, như chọn mode không phù hợp, tái sử dụng IV hoặc nonce, tự ghép các thành phần thành một giao thức riêng, nhúng khóa cứng trong source code, hoặc quản lý vòng đời khóa quá sơ sài. Vì vậy, cách tiếp cận an toàn nhất gần như luôn là dùng thư viện trưởng thành, giữ nguyên các thiết lập mặc định tốt, tận dụng framework hoặc dịch vụ quản lý khóa đáng tin cậy, và hạn chế tối đa phần mã tự viết chạm trực tiếp vào chi tiết mật mã. Nhìn theo cách đó, cryptography không phải là một vùng tri thức xa vời. Nó là một bộ công cụ nhỏ nhưng rất mạnh, miễn là đội ngũ dùng nó với đủ hiểu biết và đủ kỷ luật.
Tính ngẫu nhiên (Randomness) và định danh mờ (Opaque Identifier): ngăn chặn khả năng đoán biết và liên kết dữ liệu
Trong rất nhiều cơ chế bảo vệ của hệ thống, điều kiện đầu tiên không phải là mã hóa phức tạp mà là khả năng tạo ra các giá trị đủ khó đoán. Những giá trị như mã đặt lại mật khẩu, session ID, OTP, khóa phiên, hay mã đơn hàng gửi ra bên ngoài đều phải tránh để người khác suy ra được. Nếu chúng được tạo theo quy luật, chẳng hạn tăng dần, dựa trên timestamp, hoặc ghép từ thông tin cá nhân, kẻ tấn công có thể lần ra mẫu sinh, thực hiện liệt kê, hoặc chiếm trước tài nguyên. Vì vậy, một nền tảng rất cơ bản nhưng rất quan trọng của cryptography là nguồn sinh ngẫu nhiên đủ mạnh.
Về nguyên lý, bộ sinh số giả ngẫu nhiên (Pseudo Random Number Generator, PRNG) tạo ra chuỗi có vẻ ngẫu nhiên nhưng thực chất vẫn phụ thuộc vào seed và trạng thái nội bộ. Nếu các yếu tố này bị lộ hoặc bị suy đoán, đầu ra có thể trở nên dự đoán được. Do đó, PRNG phù hợp cho mô phỏng, lấy mẫu dữ liệu hoặc game, nhưng không phù hợp cho các giá trị liên quan đến bí mật hay an toàn hệ thống. Trong các tình huống như sinh khóa, nonce, IV, token hoặc định danh công khai khó đoán, lựa chọn đúng phải là bộ sinh số giả ngẫu nhiên an toàn về mật mã (Cryptographically Secure Pseudo Random Number Generator, CSPRNG). CSPRNG được thiết kế để đầu ra không thể bị dự đoán trong điều kiện thực tế, đồng thời khó bị suy ngược để lộ trạng thái bên trong.
Từ góc độ thiết kế phần mềm, nguyên tắc áp dụng khá rõ ràng. Hệ thống nên sử dụng CSPRNG do thư viện chuẩn, hệ điều hành hoặc dịch vụ quản lý khóa (Key Management Service, KMS) cung cấp, thay vì tự viết bộ sinh riêng. Với các định danh công khai, nên dùng opaque identifier có entropy đủ lớn, thông thường hướng tới ít nhất 128 bit, không chứa thông tin cá nhân và không làm lộ quy mô dữ liệu trong hệ thống. Cách làm đúng là tách biệt định danh công khai với khóa chính nội bộ. Bên trong cơ sở dữ liệu, hệ thống vẫn có thể dùng khóa tự tăng hoặc khóa kỹ thuật để phục vụ liên kết và tối ưu truy vấn. Tuy nhiên, khi dữ liệu đi ra ngoài hệ thống, phía người dùng hoặc đối tác chỉ nên nhìn thấy public ID ngẫu nhiên.
Tóm lại, nếu nguồn ngẫu nhiên yếu thì toàn bộ lớp bảo vệ phía sau cũng trở nên mong manh. Vì thế, việc phân biệt đúng giữa PRNG và CSPRNG không phải là một chi tiết cài đặt nhỏ, mà là một quyết định thiết kế có ảnh hưởng trực tiếp đến độ an toàn của toàn hệ thống.
Hàm băm (Hash Functions) và Tóm tắt thông điệp (Message Digests): Đảm bảo tính toàn vẹn thông qua chuyển đổi một chiều
Khi nói tới integrity, công cụ cơ bản nhất trong hộp đồ nghề mật mã là hash function và message digest. Ý tưởng rất đơn giản: thay vì phải so sánh cả một thông điệp dài, ta nén nó lại thành một chuỗi bit cố định, ví dụ 256 bit, đóng vai trò như dấu vân tay của thông điệp. Nếu chỉ cần một bit trong dữ liệu gốc thay đổi, dấu vân tay này rất có xác suất sẽ đổi theo. Về mặt khái niệm, một hàm băm mật mã đẹp phải thỏa ba tính chất then chốt:
- tính kháng tiền ảnh (Pre-image resistance): biết giá trị hash H mà không đoán lại được thông điệp gốc tương ứng, trừ khi brute-force.
- tính kháng ảnh thứ hai (Second pre-image resistance): đã biết một thông điệp M, rất khó tìm được thông điệp khác M’ sao cho hash(M) = hash(M') .
- tính kháng va chạm (Collision resistance): khó tìm được bất kỳ cặp thông điệp khác nhau nào cho cùng một giá trị hash.
Trong thực tế, chúng ta không chứng minh được không thể mà chỉ cố gắng chọn các hàm băm sao cho việc tìm ra những trường hợp này tốn tài nguyên đến mức không khả thi. Vì vậy trong phần mềm hiện đại, lựa chọn an toàn mặc định là SHA-256 hoặc SHA-512 (tuỳ theo khuyến nghị tổ chức); các họ cũ như MD5 hay SHA-1 đã không còn đủ mạnh cho quyết định an ninh và nên coi như chỉ dùng cho mục đích kế thừa.
Một chi tiết dễ bị bỏ qua là: hash không phải là danh tính. Nhiều hệ thống tiện tay cắt ngắn hash (ví dụ lấy 6-8 ký tự đầu) để hiển thị mã tham chiếu, rồi vô tình dùng luôn chuỗi ngắn đó như ID duy nhất. Làm vậy sẽ thu nhỏ không gian tìm kiếm và biến các va chạm vốn hiếm tới mức không đáng kể thành có xác suất hữu hình. Nếu cần mã ngắn, hãy coi đó chỉ là lớp hiển thị; bên dưới vẫn lưu toàn bộ digest hoặc một định danh ngẫu nhiên khác.
Hash cũng không chứng minh được nguồn gốc thông điệp. Nếu hai bên chỉ trao đổi message và hash(message) bất kỳ ai nhìn thấy cặp này đều có thể sao chép và gửi lại; kẻ tấn công không cần biết khóa gì cả, vì ở đây không hề có khóa.
Để gắn dấu vân tay này với một bí mật và biến nó thành bằng chứng mạnh hơn, chúng ta thêm khóa bí mật vào phép tính, tạo thành mã xác thực thông điệp (Message Authentication Code - MAC), điển hình là HMAC. Khi đó, chỉ những ai biết khóa mới tạo được cặp (messsage,tag) hợp lệ; kẻ tấn công không thể giả mạo. Ví dụ để sử dụng MAC cho mục đích ngăn chặn Tampering:
- Bên nhận và gửi cùng chia sẻ một khóa bí mật K trước.
- bên gửi tính tag = HMAC(K,"hello") rồi gửi kèm: message = "hello" tag.
- bên nhận tự tính lại tag' = HMAC(K,"hello") và so sánh constant-time với tag. Nếu ai đó (mallory) sửa 1 byte, ví dụ "hello" → "hallo" nhưng vẫn dùng tag cũ, thì HMAC(K,"hallo") ≠ tag ⇒ bị từ chối.
Khi dùng MAC, ta mới chỉ bảo vệ được tính toàn vẹn với thông điệp không bị sửa đổi, chứ chưa bảo vệ được freshness (tính mới). Một kiểu tấn công điển hình là relay / replay: kẻ tấn công đơn giản gửi lại một cặp (messsage,tag) đã được hệ thống chấp nhận trước đó, ví dụ gửi lại lệnh đặt mua 3 mặt hàng X nhiều lần. Do MAC vẫn khớp với chính thông điệp cũ ấy, kiểm tra toàn vẹn vẫn ‘pass’, và hệ thống sẽ xử lý lại yêu cầu. Để dùng MAC mà tránh bị relay, ta phải gắn thêm ngữ cảnh thời gian và ngữ cảnh duy nhất cho từng thông điệp:
- cửa sổ thời gian (Timestamp window): mỗi thông điệp mang theo thời điểm tạo; phía nhận chỉ chấp nhận nếu thời gian nằm trong một khoảng cho phép (ví dụ ≤ 300 giây). Các thông điệp quá hạn bị từ chối, dù MAC vẫn hợp lệ.
- Nonce hoặc số thứ tự per-sender: người nhận giữ bảng nonce/sequence cho từng client; mỗi giá trị chỉ dùng một lần. Nếu thấy nonce hoặc số thứ tự đã dùng rồi, hệ thống coi đó là replay và từ chối.
- chìa khóa bất biến (Idempotency key) cho API: với các API hợp lệ được gọi lại (do retry mạng, client timeout…), ta yêu cầu client gửi kèm một idempotency-key. Server lưu trạng thái theo key này và đảm bảo cùng một key chỉ được xử lý một kết quả duy nhất.
Một quy trình điển hình sẽ là:
- kiểm tra dấu thời gian còn trong cửa sổ chấp nhận;
- kiểm tra và lưu nonce/sequence tương ứng, đảm bảo không tái sử dụng;
- tính lại MAC từ thông điệp và so sánh với tag bằng hàm constant-time;
Chỉ khi cả ba bước đều đạt, yêu cầu mới được xử lý. Nhờ vậy, MAC vẫn làm nhiệm vụ bảo vệ toàn vẹn, còn lớp logic bổ sung đảm bảo rằng mỗi thông điệp chỉ có thể sống đúng một lần.
Khi thiết kế cơ chế MAC cho các API, ta không nên chỉ hash lên bất cứ chuỗi nào tiện tay lấy được. Thay vào đó, thông điệp cần được đưa về một canonical form rồi mới tính MAC. Một cách phổ biến là nối các thành phần quan trọng của request theo thứ tự cố định, chẳng hạn: method | path | timestamp | nonce | body. Như vậy, cùng một yêu cầu POST /orders với cùng payload và cùng thời điểm sẽ luôn tạo ra chính xác một chuỗi chuẩn, bất kể client có format JSON thế nào; server chỉ việc tái dựng lại đúng chuỗi đó để tính và kiểm tra MAC. Điều này tránh được các lỗi rất khó chịu khi chỉ thay đổi thứ tự field hoặc khoảng trắng mà MAC lại khác.
Với payload JSON, bước đưa về dạng chuẩn càng quan trọng hơn. Thực tế triển khai thường có một hàm chuẩn hóa JSON: sắp xếp khóa theo thứ tự cố định, loại bỏ khoảng trắng/thụt dòng không cần thiết, thống nhất encoding. Sau chuẩn hóa, mọi bản thể hiện của cùng một cấu trúc dữ liệu đều trở thành cùng một chuỗi byte duy nhất, là đầu vào ổn định để tính MAC. Nhờ vậy, ta có thể tin rằng nếu MAC trùng khớp thì thông điệp thật sự không bị sửa đổi.
Khóa bí mật dùng cho HMAC không bao giờ được hard-code trong source hay lưu ở file cấu hình thuần văn bản. Thay vào đó, ta ủy thác việc giữ khóa cho các hệ thống chuyên dụng như KMS (Key Management Service) hoặc HSM (Hardware Security Module). Ứng dụng chỉ tương tác với KMS/HSM qua API, ví dụ: gửi chuỗi chuẩn hóa sang để dịch vụ tính giúp HMAC và trả về tag, hoặc rút khóa tạm thời trong một phiên được giám sát. Cách làm này giảm mạnh rủi ro lộ khóa, đặc biệt trong bối cảnh log, crash dump, hay nhân sự nội bộ.
Cuối cùng, cần nhớ rằng HMAC chỉ bảo vệ integrity và authenticity, chứ không che giấu nội dung. Nếu payload cũng cần confidentiality (secret), chẳng hạn chứa PII, thông tin tài chính thì một giải pháp tốt hơn là sử dụng chế độ mã hóa có xác thực (Authenticated Encryption with Associated Data, AEAD ) như AES-GCM, vốn kết hợp mã hóa và xác thực trong cùng một primitive. Lúc này, thay vì encrypt rồi lại MAC thêm một lớp, ta chỉ cần một bước AES-GCM: bản mã nhận được vừa được che giấu nội dung, vừa kèm một authentication tag để phát hiện mọi sửa đổi.
Cơ bản về mã hóa đối xứng (Symmetric Encryption): Bảo vệ tính bảo mật bằng khóa chia sẻ
Symmetric encryption là xương sống của mật mã hiện đại: cùng một khóa bí mật được dùng để mã hóa và giải mã. Nếu dùng đúng cách, nó bảo vệ tính bí mật của dữ liệu cả khi truyền trên kênh không an toàn lẫn khi lưu trữ, với hiệu năng rất cao và được hỗ trợ rộng rãi trong phần cứng/phần mềm (điển hình là AES). Tuy nhiên, sự an toàn không đến từ một hàm AES thần thánh, mà từ tập hợp các yếu tố: thuật toán đúng, mode phù hợp, phân phối khóa/IV/nonce chuẩn, padding đúng cách và cơ chế bảo vệ toàn vẹn đi kèm.
- Mô hình đồ chơi (toy model) dùng XOR và One-Time Pad
Mô hình đồ chơi (toy model) dùng XOR và one-time pad cho ta trực giác đầu tiên về mã hóa đối xứng (symmetric encryption). Gọi M là bản rõ (message), K là khóa bí mật, và C là bản mã (ciphertext). Cả mã hóa và giải mã đều dùng cùng một phép XOR:
C=M ⊕ K, M = C ⊕ K
ví dụ: M = 'Hi' = 1000100001101001; K = 1101001001011010 ⇒ M ⊕ K = C
Nếu K được sinh ngẫu nhiên thật sự, dài bằng M và chỉ dùng một lần, ta có mô hình one-time pad cổ điển, về mặt lý thuyết là tuyệt đối bí mật. Từ C không thể suy ra bất cứ thông tin nào về M nếu không biết K.
Vấn đề là one-time pad gần như không thể vận hành trong hệ thống thực tế, ví phải phân phối lượng khóa khổng lồ và đảm bảo không bao giờ tái sử dụng, và chính việc tái sử dụng khóa mới là chỗ sai nhất.
- Nếu ta mã hóa hai thông điệp M1,M2 với cùng khóa K, ta có C1=M1 ⊕ K1, C2 = M2 ⊕ K .
- Từ đó, kẻ tấn công có thể tính C1 ⊕ C2 = M1 ⊕ M2 , làm lộ cấu trúc quan hệ giữa hai bản rõ, mở ra nhiều tấn công suy luận.
Điểm rút ra là rất rõ: với mô hình XOR, toàn bộ bí mật nằm ở khóa, và khóa không được reuse một cách ngây thơ. Các block cipher hiện đại như AES thực chất vẫn dựa trên ý tưởng biến đổi dữ liệu nhiều lớp, trong đó có XOR kết hợp với các phép trộn rất tinh vi để xóa cấu trúc của bản rõ. Nhưng nếu dùng sai mode hoặc reuse IV hay nonce, hệ thống vẫn có thể rò rỉ thông tin dù thuật toán lõi rất mạnh.
- Mã khối (Block Ciphers) và Chế độ hoạt động (Modes of Operation)
Trong thực tế, hệ thống không dùng one-time pad mà dùng mã khối (block cipher) như AES, với kích thước khối cố định, thường là 128 bit. Khi dữ liệu dài hơn một khối, nó sẽ được chia thành nhiều khối 128 bit; khối cuối thường cần đệm (padding) theo chuẩn như PKCS#7 trước khi mã hóa.
Tuy nhiên, thuật toán thôi là chưa đủ. Chế độ hoạt động (mode of operation) cũng quan trọng không kém. Với chế độ đơn giản nhất là ECB, mỗi khối bản rõ được mã hóa độc lập: C_i =AES_k(M_i) .Vì vậy, hai khối bản rõ giống nhau sẽ tạo ra hai khối bản mã giống nhau. Khi dữ liệu có cấu trúc lặp, như ảnh bitmap, mẫu hình gốc vẫn có thể hiện ra trên bản mã. Đây là hiện tượng rò rỉ mẫu (pattern leak).
Vì lý do đó, trong thiết kế hệ thống cần tuân theo vài nguyên tắc cơ bản. Không dùng AES-ECB trực tiếp cho dữ liệu ứng dụng. ECB chỉ nên được xem như một primitive bên trong thư viện, không phải mode để dùng ở cấp hệ thống. Thay vào đó, nên dùng các mode hiện đại như CTR, CBC, và đặc biệt là các mode mã hóa có xác thực (AEAD) như AES-GCM, để vừa bảo vệ tính bí mật vừa bảo vệ tính toàn vẹn.
Với các mode dựa trên nonce hoặc IV, mỗi lần mã hóa dưới cùng một khóa phải dùng một nonce hoặc IV khác nhau. Nếu reuse nonce hoặc IV, nhiều thuộc tính an toàn quan trọng sẽ bị phá vỡ, tương tự như việc reuse key trong mô hình XOR.
Tóm lại, mã hóa đối xứng (symmetric encryption) làm việc trên từng khối dữ liệu, còn mode of operation quyết định cách các khối đó được nối lại thành một cơ chế mã hóa hoàn chỉnh. Dùng sai mode không chỉ làm giảm mức an toàn, mà còn có thể làm lộ cấu trúc dữ liệu và mở đường cho các tấn công phân tích bản mã.
- Quản lý khóa (Key Management): bài toán khó hơn cả mã hóa
Một thực tế rất quan trọng là mã hóa chỉ có giá trị khi khóa được bảo vệ tốt nhưng vẫn sẵn sàng cho hệ thống sử dụng khi cần. Thuật toán có thể đã được thư viện hiện thực rất tốt, nhưng phần khó hơn lại nằm ở cách đội phát triển quản lý khóa trong suốt vòng đời của nó.
Có một số nguyên tắc thiết kế cần giữ rõ.
- Chỉ giấu khóa, không giấu thuật toán. Hệ thống phải luôn giả định đối thủ biết mình đang dùng AES, GCM hay thuật toán nào khác. Thứ cần bảo vệ là giá trị khóa, không phải tên thuật toán.
- Khóa phải được lưu trong dịch vụ quản lý khóa (Key Management Service, KMS), mô đun bảo mật phần cứng (Hardware Security Module, HSM), hoặc kho bí mật an toàn, thay vì hard-code trong source code hay để trong cấu hình dạng thuần văn bản. Việc truy cập kho khóa phải có kiểm soát quyền, có audit log, và có quy trình rõ cho tạo mới, phân phối, xoay vòng và thu hồi.
- Cần giảm phạm vi phơi lộ của khóa. Không nên có một khóa dùng cho mọi mục đích. Thay vào đó, nên dùng cơ chế dẫn xuất khóa như hàm dẫn xuất khóa dựa trên HMAC (HMAC-based Key Derivation Function, HKDF) để tách riêng khóa cho từng ngữ cảnh, như khóa cho kênh truyền, khóa cho dữ liệu lưu trữ, hay khóa cho token. Cách này giúp giới hạn thiệt hại nếu một khóa con bị lộ.
- Ngay từ đầu phải chuẩn bị cho khôi phục thảm họa (Disaster Recovery). Kiến trúc cần cho phép xoay vòng khóa, mã hóa lại dữ liệu và cập nhật cấu hình mà không làm hệ thống dừng quá lâu, đồng thời vẫn kiểm soát chặt ai có quyền khởi động quy trình đó.
Vì vậy, mã hóa đối xứng (symmetric encryption) không chỉ là gọi một hàm AES. Nó là một tập hợp quyết định thiết kế gồm chọn thuật toán và mode phù hợp, sinh và phân phối khóa đúng cách, bảo đảm mỗi bản mã dùng nonce hoặc IV khác nhau, và xây dựng hạ tầng quản lý khóa đủ chặt. Chỉ khi các mảnh ghép đó được đặt đúng chỗ, hệ thống mới có được lớp bảo vệ thực sự vững chắc.
Mã hóa bất đối xứng (Asymmetric Encryption) và Trao đổi khóa - Bảo vệ bí mật không cần khóa chia sẻ
Trong các phần trước, chúng ta xem mã hoá đối xứng như xương sống của crypto hiện đại: một khoá bí mật dùng chung, thuật toán nhanh, rất phù hợp để bảo vệ lưu lượng và dữ liệu lưu trữ. Nhưng còn một câu hỏi bị bỏ ngỏ: làm thế nào để hai bên có được khoá bí mật chung ngay từ đầu, đặc biệt trên một mạng hoàn toàn không tin cậy? Câu trả lời nằm ở mã hoá bất đối xứng và thoả thuận khoá.
- Hàm một chiều và cặp khóa công khai/bí mật
Mã hóa bất đối xứng (public-key cryptography) hoạt động theo một ý tưởng ngược trực giác: bất kỳ ai cũng có thể dùng khóa công khai (public key) của bạn để mã hóa dữ liệu gửi cho bạn, nhưng chỉ bạn, người giữ khóa bí mật (private key), mới có thể giải mã.
Mỗi thực thể có một cặp khóa. Public key được chia sẻ rộng rãi, dùng để mã hóa hoặc để người khác kiểm tra chữ ký số của bạn. Private key được giữ kín, dùng để giải mã hoặc để ký. Điểm cốt lõi là từ public key không thể suy ra private key trong thực tế.
Nhờ đó, public-key cryptography tạo ra một cơ chế một chiều: thao tác theo chiều thuận như mã hóa hoặc kiểm tra chữ ký là khả thi với public key, còn thao tác ngược như giải mã hoặc tạo chữ ký chỉ thực hiện được khi có private key. Chính tính bất đối xứng này làm nền tảng cho các cơ chế như trao đổi khóa, chữ ký số và PKI trong các hệ thống hiện đại.
- RSA và cái bẫy phân tích thừa số
Một họ thuật toán kinh điển cho mã hoá bất đối xứng là RSA. Ý tưởng cốt lõi:
- Dễ: nhân hai số nguyên tố rất lớn với nhau.
- Khó: từ tích đó phân tích ngược ra hai thừa số ban đầu (bài toán factoring).
Quy trình tạo khoá RSA (tóm lược):
- Chọn ngẫu nhiên hai số nguyên tố p,q.
- Tính N = p.q và một số phụ trợ φ(N).
- Chọn khóa công khai pk = (N,e) thỏa mãn điều kiện toán học phù hợp.
- Tính khóa bí mật d từ sk =φ(N) và e , giữ kín d công bố (N,e).
Encrypt: C = Encrypt_pk(M) dùng khóa công khai của Alice.
Decrypt: M = Decrypt_sk(C) dùng khóa bí mật của Alice.
Khoá công khai có thể tạo điều kiện cho tấn công đoán mẫu (chosen-plaintext). Nếu ta mã hoá trực tiếp thông điệp thô, kẻ tấn công có thể thử rất nhiều thông điệp đoán trước và so sánh kết quả. Vì vậy, mọi triển khai RSA thực tế đều dùng padding ngẫu nhiên an toàn (chẳng hạn RSA-OAEP cho mã hoá). Điểm rút ra cho người thiết kế hệ thống:
- Không tự chế RSA; luôn dùng primitive của thư viện chuẩn (RSA-OAEP cho mã hoá, RSA-PSS cho chữ ký).
- Chỉ quan tâm đến cách dùng đúng (chọn padding, độ dài khoá, cách lưu khoá), không tự viết thuật toán cấp thấp.
- Vai trò thực tiễn của mã hóa bất đối xứng
Mã hóa bất đối xứng thường không được dùng để bảo vệ toàn bộ lưu lượng, vì chi phí tính toán cao hơn nhiều so với mã hóa đối xứng. Khóa dài hơn, thao tác chậm hơn, và tiêu tốn CPU nhiều hơn.
Trong các giao thức hiện đại, mã hóa bất đối xứng chủ yếu giữ hai vai trò.
- Vận chuyển khóa: một bên sinh ngẫu nhiên khóa đối xứng, mã hóa khóa đó bằng public key của bên kia rồi gửi sang. Bên nhận dùng private key để giải mã, sau đó cả hai dùng chung khóa đối xứng này để mã hóa dữ liệu thực.
- Xác thực và chữ ký số: private key dùng để ký, còn public key dùng để kiểm tra chữ ký. Cơ chế này cho phép gắn danh tính với khóa thông qua hạ tầng khóa công khai (Public Key Infrastructure, PKI) và chứng thư số (digital certificate).
Vì vậy, vai trò chính của mã hóa bất đối xứng không phải là chở toàn bộ dữ liệu, mà là thiết lập niềm tin ban đầu và trao khóa an toàn. Sau đó, phần dữ liệu khối lượng lớn sẽ được bảo vệ bằng mã hóa đối xứng để đạt hiệu năng tốt hơn.
- Trao đổi khóa: Diffie-Hellman và Elliptic Curve Diffie-Hellman
Bên cạnh RSA, một ý tưởng cực kỳ quan trọng khác là trao đổi khóa (key exchange), với đại diện nổi bật là Diffie-Hellman (DH) và biến thể Elliptic-Curve Diffie-Hellman (ECDH). Có thể mô tả mục tiêu đơn giản như sau:
- Alice và Bob không có khoá chung từ trước,
- kênh truyền hoàn toàn bị nghe lén,
- nhưng cuối cùng suy ra cùng một bí mật chung, trong khi Mallory (kẻ nghe lén) chỉ thấy các giá trị công khai.
Quy trình DH cổ điển được biểu diễn như sau:
- Agree publicly on a prime p and a base g where 1 < g < p.
- Alice picks random a, sends A = g^a (mod p).
- Bob picks random b , sends B = g^b (mod p).
- Alice computes S = B^a(mod p) ; Bob computes S = A^b (mod p)
 .
. - Both get the same S (discrete-log trapdoor).
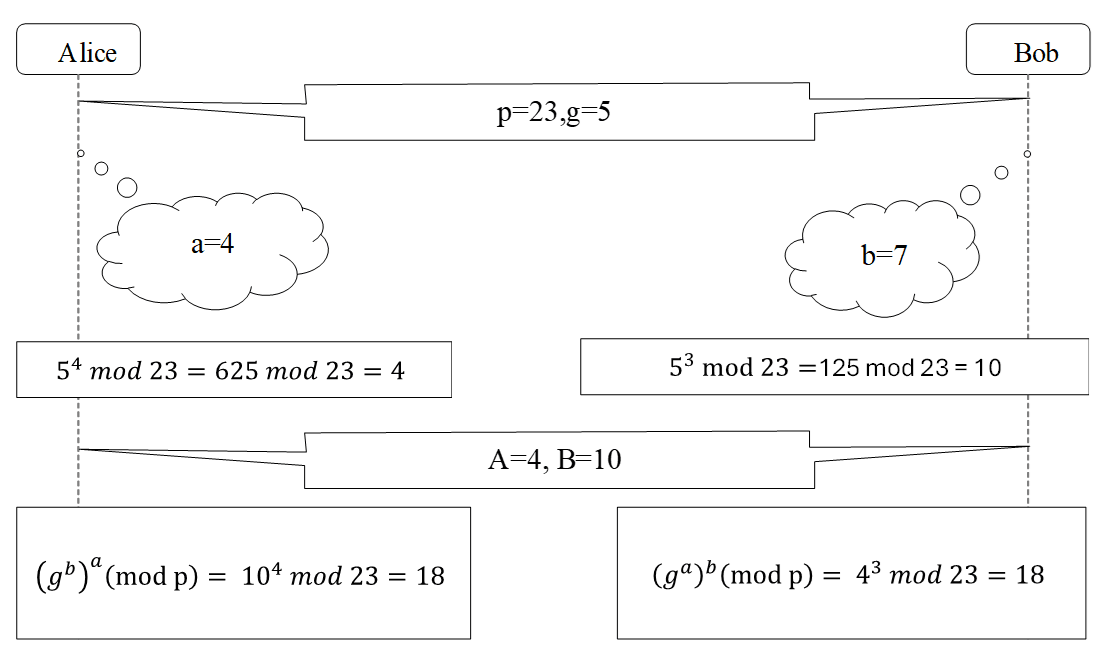
Hình 2. Ví dụ về key exchange sử dụng quy trình DH.
Quá trình này làm cho Mallory chỉ thấy p,g,A,B và phải giải bài toán logarit rời rạc cực khó để suy ra S. Hình 2 biểu diễn một numerial illustration của quy trình DH.
Trong thực tế, các hệ thống hiện đại thường dùng ECDH:
- Dựa trên toán học đường cong elliptic, cho mức an toàn tương đương với khoá ngắn hơn (ví dụ ECDH-P-256 so với DH 2048-bit).
- Hiệu năng tốt hơn, nhất là trên thiết bị di động.
Một biến thể quan trọng là ephemeral ECDH (ECDHE):
- Mỗi phiên kết nối sinh khoá ECDH tạm thời khác nhau.
- Sau khi phiên kết thúc, nếu khoá dài hạn bị lộ thì các phiên cũ vẫn an toàn - tính chất này gọi là forward secrecy.
Mã hoá bất đối xứng và thoả thuận khoá không thay thế mã hoá đối xứng; chúng đóng vai trò lớp khởi tạo niềm tin và khoá bí mật, để rồi toàn bộ lưu lượng được mã hoá nhanh và hiệu quả bằng các công cụ.
Chữ ký số và Hạ tầng khóa công khai (PKI)
Ở các phần trước chúng ta dùng mật mã để giữ confidentiality và integrity. Tuy nhiên sau khi kênh đã được bảo vệ, vẫn còn một câu hỏi bản chất: Thông điệp này thực sự đến từ ai?, và sau này người đó có thể chối bỏ việc đã gửi hay không? Đó là bài toán origin authentication và non-repudiation. Chữ ký số và PKI là lớp công cụ trả lời hai câu hỏi này.
- Chữ ký số
Về trực giác, chữ ký số đóng vai trò giống chữ ký tay trên giấy tờ, nhưng với hai điểm quan trọng:
- Chỉ chủ sở hữu khóa bí mật mới tạo được chữ ký hợp lệ cho một thông điệp cho trước;
- Bất kỳ ai có khóa công khai tương ứng đều có thể kiểm tra và tin rằng thông điệp thực sự do người đó ký, và người ký khó có thể chối bỏ về sau.
Nói cách khác, chữ ký số cung cấp:
- Authenticity: thông điệp gắn với một danh tính cụ thể.
- Integrity: nếu nội dung bị sửa, chữ ký sẽ không còn đúng.
- Non-repudiation: về mặt kỹ thuật và pháp lý, người nắm khóa bí mật khó phủ nhận việc đã ký.
Trong Hình 3, phía trái là mật mã đối xứng: cùng một khóa bí mật được dùng để mã hóa và giải mã, nên chỉ hai bên biết khóa mới đọc được dữ liệu, nhưng không ai chứng minh được với bên thứ ba ai là người gửi. Phía phải là mật mã bất đối xứng: khóa bí mật dùng để sign, khóa công khai dùng để verify chữ ký. Điều này cho phép bất kỳ ai có khóa công khai đều kiểm chứng được chữ ký của Alice, mà Alice vẫn giữ kín khóa bí mật.
Một người có thể đặt câu hỏi Vì sao chữ ký số khác với MAC? ta đã dùng MAC/HMAC để đảm bảo toàn vẹn và xác thực giữa hai bên chia sẻ một khóa bí mật chung. Tuy nhiên:
- Với MAC, cả hai bên đều có thể tạo mã MAC cho một thông điệp bất kỳ. Nếu xảy ra tranh chấp, không thể chứng minh cho bên thứ ba rằng chính bên kia đã gửi.
- Với chữ ký số, chỉ người nắm khóa bí mật mới tạo được chữ ký hợp lệ, trong khi ai có khóa công khai cũng kiểm tra được. Vì vậy chữ ký thích hợp cho các kịch bản yêu cầu bằng chứng pháp lý (hợp đồng điện tử, hóa đơn, log quan trọng, cập nhật phần mềm,…).
Một cách ngắn gọn: MAC phù hợp cho tin cậy lẫn nhau trong nội bộ, còn chữ ký số phù hợp cho bằng chứng hướng ra bên ngoài. h = Hash(M)
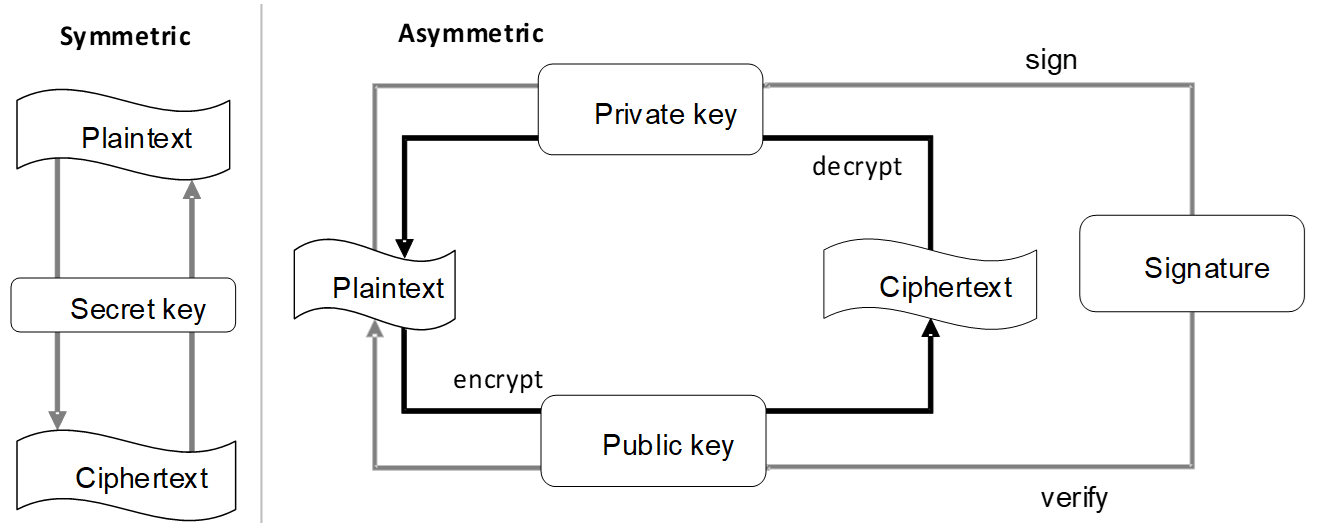
Hình 3. Chữ ký số so với mã hóa đối xứng và bất đối xứng.
- Quy trình ký và xác thực chữ ký
Trong thực tế, chúng ta không ký trực tiếp lên toàn bộ thông điệp mà ký lên digest của nó:
- Người gửi (Alice) tính hash của thông điệp: S = Sign_priv_A(h) ví dụ sử dụng SHA-256.
- Alice dùng khóa bí mật của mình để tính chữ ký: (M,S)
- Alice gửi cho Bob cặp h' = Hash(M).
- Bob nhận và tự tính lại hash: Verify_pub_A(h',S) = {OK , NOT OK} .
- Bob dùng chung khóa công khai của Alice để kiểm tra: Verify_pub_A(h',S) = {OK, NOT OK} . Nếu kiểm tra thành công, Bob tin rằng thông điệp không bị sửa, đúng là khóa bí mật tương ứng với pub_A đã tạo ra chữ ký này.
3. Hạ tầng khóa công khai (PKI) và chứng chỉ số
Chữ ký số (digital signature) chỉ có giá trị khi bên nhận chắc chắn rằng khóa công khai (public key) đang dùng để kiểm tra thực sự thuộc về đúng chủ thể, chứ không phải khóa do kẻ tấn công thay thế. Vì vậy, vấn đề cốt lõi không chỉ là có public key, mà là lấy public key đáng tin từ đâu. Nếu public key chỉ được gửi qua email hoặc đăng lên website mà không có cơ chế xác thực, attacker hoàn toàn có thể tráo bằng khóa của mình.
Giải pháp cho bài toán này là hạ tầng khóa công khai (Public Key Infrastructure, PKI). Trong PKI, tổ chức chứng thực (Certificate Authority, CA) đóng vai trò xác minh danh tính của chủ thể như domain, tổ chức hoặc cá nhân, rồi phát hành chứng thư số (digital certificate). Chứng thư này chứa public key, thông tin định danh và metadata liên quan, sau đó được CA ký bằng khóa bí mật của chính CA. Nhờ đó, public key không còn là một giá trị trôi nổi, mà trở thành một khóa đã được ràng buộc với danh tính cụ thể.
PKI vận hành dựa trên chuỗi tin cậy (trust chain). Ở gốc là Root CA, thường là self-signed và đã được nhúng sẵn trong trust store của hệ điều hành, trình duyệt hoặc thiết bị. Dưới đó là các Intermediate CA, được CA cấp trên ký. Cuối cùng là chứng thư của thực thể cuối (end-entity certificate), gắn với public key của website, service hoặc người dùng cụ thể. Như Hình 4 cho thấy, phần mềm sẽ kiểm tra chữ ký từ end-entity certificate ngược lên Intermediate CA rồi tới Root CA, và chỉ chấp nhận nếu toàn bộ chuỗi đều hợp lệ.
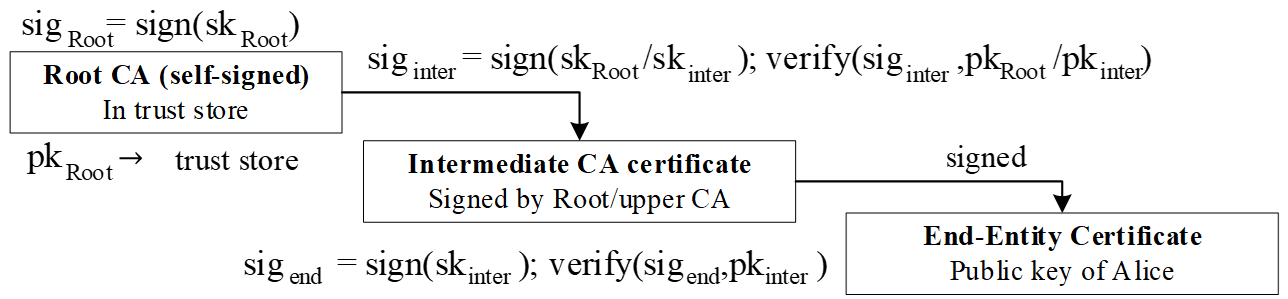
Hình 4. Chuỗi chứng thư: Root CA → Intermediate → End-entity.
Một chứng thư thường chứa các trường chính như Subject để mô tả danh tính chủ thể, Issuer để chỉ CA phát hành, thời hạn hiệu lực, public key, số sê-ri, mục đích sử dụng khóa, các subject alternative names (SAN), và chữ ký của CA. Các trường này giúp phần mềm không chỉ kiểm tra được tính hợp lệ của certificate, mà còn kiểm tra được nó có đúng để dùng trong ngữ cảnh hiện tại hay không.
Quy trình sử dụng có thể tóm tắt như sau. Alice tạo cặp khóa và gửi public key cùng thông tin định danh cho CA. CA xác minh danh tính rồi phát hành certificate chứa public key của Alice và ký lên đó. Khi Alice gửi certificate cho Bob, chẳng hạn trong quá trình bắt tay TLS, phần mềm phía Bob sẽ kiểm tra chữ ký của certificate theo trust chain, đối chiếu danh tính hoặc domain trong certificate với endpoint đang kết nối, và kiểm tra thêm thời hạn hiệu lực hoặc trạng thái thu hồi nếu cần. Nếu mọi kiểm tra đều hợp lệ, Bob mới tin rằng public key trong certificate thực sự thuộc về Alice. Khi đó, Bob có thể dùng public key này để mã hóa khóa phiên gửi cho Alice hoặc để kiểm tra chữ ký trên thông điệp hay bản cập nhật phần mềm. Hình 5 minh họa đúng luồng tin cậy này giữa Alice, CA hoặc trust store, và Bob.
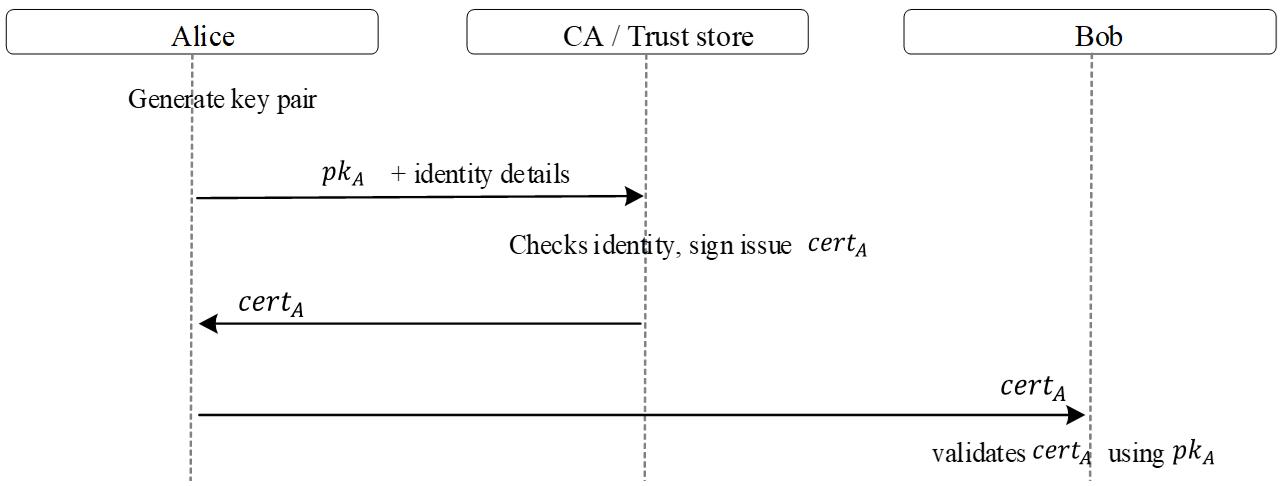
Hình 5. Luồng tin cậy: Alice - CA/Trust Store – Bob.
Tóm lại, PKI giải quyết bài toán mà chữ ký số tự thân không giải quyết được, đó là làm sao biết public key thực sự thuộc về ai. Nếu không có lớp xác thực danh tính này, public key cryptography sẽ thiếu nền tảng trust để vận hành an toàn trên Internet.
- Vòng đời của khóa và chứng chỉ số
Chữ ký số (digital signature) và hạ tầng khóa công khai (Public Key Infrastructure, PKI) chỉ an toàn khi khóa bí mật được bảo vệ tốt và vòng đời khóa được quản trị nghiêm túc. Vì vậy, thiết kế không thể dừng ở chỗ có ký hay có chứng thư, mà phải đi tiếp tới quản lý khóa (key management) và quản lý dữ liệu (data lifecycle).
Với vòng đời khóa, có bốn bước chính. Ở bước tạo khóa (Create), khóa phải được sinh từ bộ sinh số ngẫu nhiên an toàn về mật mã (Cryptographically Secure Pseudo-Random Number Generator, CSPRNG) hoặc qua dịch vụ quản lý khóa (Key Management Service, KMS). Các khóa gốc như customer master key (CMK) nên nằm trong thiết bị bảo mật phần cứng (Hardware Security Module, HSM), KMS hoặc vault, kèm phân tách nhiệm vụ quản trị. Ở bước sử dụng (Use), ứng dụng dùng CMK để quản lý các khóa mã hóa dữ liệu (Data Encryption Key, DEK) hoặc để ký thông điệp, và mọi truy cập phải đi qua role hoặc policy rõ ràng. Ở bước quay vòng (Rotate), khóa cần được thay định kỳ hoặc khi có sự cố; nên ưu tiên bọc lại DEK dưới CMK mới trước, chỉ mã hóa lại dữ liệu khi thực sự cần. Ở bước thu hồi (Retire), khóa cũ phải được thu hồi, lên lịch xóa an toàn, dọn cache và các bản sao, đồng thời lưu lại audit log để chứng minh việc hủy.
Song song với vòng đời khóa là vòng đời dữ liệu, từ thu thập, sử dụng, chia sẻ, lưu trữ cho đến lưu trữ lâu dài hoặc xóa bỏ. Ở mỗi giai đoạn, hệ thống phải xác định rõ thời hạn sống của dữ liệu (TTL) hoặc retention, mã hóa dữ liệu khi lưu trữ bằng DEK và bọc DEK dưới CMK. Khi dữ liệu không còn lý do để giữ lại, cần áp dụng xóa an toàn (secure deletion), thường bằng cách xóa khóa hoặc phần khóa tương ứng để bản mã trở nên vô dụng, kết hợp với việc dọn cache, dọn bản sao và ghi log cho thao tác crypto-shred.
Một thực hành tốt là xem quản lý khóa và dữ liệu như một phần của PKI nội bộ. Mọi khóa dùng cho chữ ký, mã hóa hay xác thực dịch vụ đều nên được sinh từ nguồn ngẫu nhiên an toàn, lưu trong HSM hoặc KMS, được gắn nhãn rõ mục đích sử dụng, và đi kèm quy trình quay vòng, thu hồi và hủy bỏ.
Khi đưa digital signature và PKI vào hệ thống, có vài nguyên tắc cần giữ chặt. Không tự hiện thực thuật toán, mà dùng primitive chuẩn từ thư viện hoặc nền tảng đáng tin cậy. Phân biệt rõ vai trò từng loại khóa: khóa nào để mã hóa, khóa nào để ký, khóa nào chỉ để bọc DEK. Luôn kiểm tra đúng danh tính trong chứng thư, như subject hoặc subject alternative name (SAN), phải khớp với endpoint hoặc tài khoản đang được xác thực. Cuối cùng, toàn bộ vòng đời khóa và chứng thư phải có quy trình phát hành, quay vòng, thu hồi và hủy bỏ kèm audit đầy đủ.
Nếu làm đúng, digital signature và PKI sẽ trở thành lớp xương sống của kiến trúc bảo mật: kênh giao tiếp có danh tính rõ ràng, bản cập nhật có thể xác thực nguồn gốc, và mọi khóa bí mật đều có một hành trình được kiểm soát từ đầu đến cuối.
Tổng kết
Mật mã học (cryptography) nên được xem như một công cụ giảm thiểu ở mức kiến trúc (architectural mitigation tool), có nhiệm vụ bảo vệ tính bí mật (confidentiality), tính toàn vẹn (integrity), tính xác thực (authenticity) và trách nhiệm giải trình (accountability) khi được đặt đúng vị trí trong hệ thống và được quản lý xuyên suốt toàn bộ vòng đời của nó.