1. GEO là gì và tại sao nó quan trọng ngay lúc này?
Trong giai đoạn 2024 đến 2026, hành vi tìm kiếm thông tin của người dùng đã trải qua một cuộc dịch chuyển căn bản. Google Search tích hợp AI Overviews ngay trong trang kết quả đầu tiên, Microsoft Bing triển khai Copilot như một lớp phủ trực tiếp lên nội dung web, và Perplexity AI xử lý hàng chục triệu truy vấn mỗi ngày mà người dùng không cần nhấp vào bất kỳ website nào. Người dùng nhận được câu trả lời tổng hợp từ AI, được trích dẫn từ một số rất ít nguồn được chọn lọc.
Điều này tạo ra một thực trạng kỹ thuật mới và đáng chú ý: một website có thể đứng top 3 trong kết quả Google Search nhưng không bao giờ được ChatGPT hay Perplexity trích dẫn, trong khi một website ở vị trí thứ 15 lại liên tục được các AI hệ thống đề xuất. Hai chỉ số này không tương quan trực tiếp vì chúng đo lường hai chiều cạnh khác nhau của khả năng hiện diện nội dung trên internet.
Định nghĩa: GEO (Generative Engine Optimization) là tập hợp các kỹ thuật tối ưu hóa website nhằm tăng xác suất nội dung của website được các mô hình ngôn ngữ lớn (LLM) chọn làm nguồn trích dẫn khi tổng hợp câu trả lời cho người dùng.
Khái niệm GEO xuất hiện lần đầu trong nghiên cứu học thuật vào khoảng năm 2023 và trở nên phổ biến trong cộng đồng phát triển web từ giữa năm 2024, khi các AI search engines bắt đầu chiếm thị phần đáng kể trong lưu lượng truy vấn thông tin. Cộng đồng kỹ thuật đã bắt đầu nhận ra rằng các yếu tố quyết định khả năng AI trích dẫn về cơ bản khác với các yếu tố xếp hạng của Google PageRank.
Hình 1 dưới đây minh họa cơ chế hoạt động của hệ sinh thái AI Search: cùng một truy vấn của người dùng được gửi đến nhiều hệ thống AI khác nhau, mỗi hệ thống tổng hợp câu trả lời từ một tập nguồn được chọn lọc. Trong thực tế, chỉ một đến hai website xuất hiện trong câu trả lời cuối cùng, trong khi phần lớn website dù có nội dung phù hợp vẫn bị bỏ qua do các rào cản kỹ thuật.
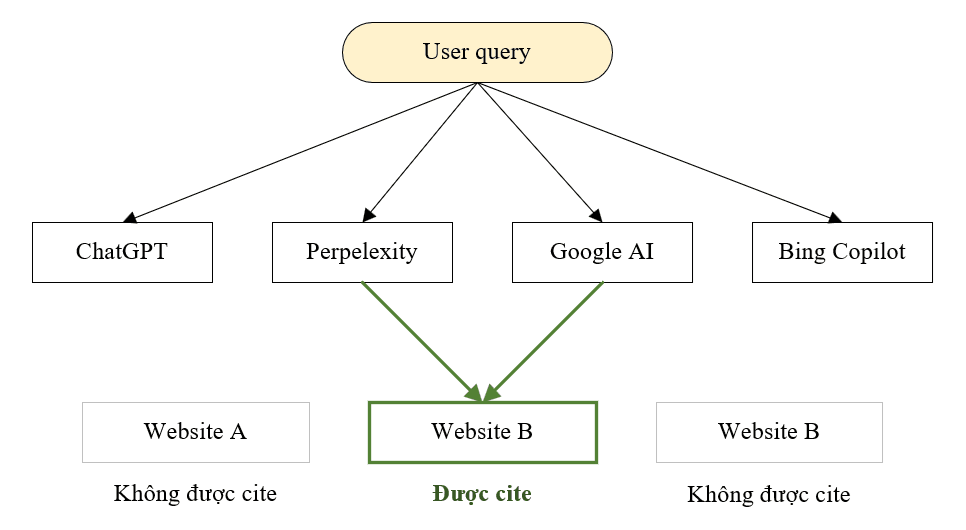
Hình 1. Hệ sinh thái AI Search 2026: cùng một truy vấn, AI chọn lọc rất ít website để cite. Website được tối ưu GEO có xác suất xuất hiện cao hơn đáng kể.
2. Sự khác biệt kỹ thuật giữa SEO và GEO
SEO truyền thống và GEO không phải là hai phương pháp loại trừ nhau mà là hai lớp tối ưu hóa chồng lên nhau với mục tiêu và đối tượng khác nhau. SEO tốt là điều kiện cần nhưng chưa đủ để được AI trích dẫn, vì các AI crawler đánh giá nội dung theo tiêu chí hoàn toàn khác với các search engine crawler truyền thống.
Về phía SEO truyền thống, mục tiêu cốt lõi là đưa website vào top 10 kết quả tìm kiếm hữu cơ. Để đạt được điều này, các kỹ thuật chủ yếu tập trung vào xây dựng backlink chất lượng cao, tối ưu mật độ từ khóa, cải thiện Core Web Vitals (tốc độ tải trang, độ ổn định bố cục), và đảm bảo khả năng index của Googlebot và Bingbot. Đơn vị đo lường thành công là organic click-through rate (tỷ lệ nhấp chuột từ kết quả tìm kiếm).
Về phía GEO, mục tiêu là đảm bảo website được AI chọn làm nguồn trả lời. Để đạt được điều này, các kỹ thuật tập trung vào việc cung cấp thông tin rõ ràng về thực thể tổ chức, đảm bảo nội dung có cấu trúc câu trả lời đầy đủ, triển khai structured data (Schema.org), và cung cấp tín hiệu uy tín (authority signals) mà AI có thể đánh giá. Đơn vị đo lường là AI citation rate, đây là tần suất website được đề cập trong câu trả lời của AI.
| SEO truyền thống | GEO (mục tiêu mới) |
|---|---|
| Xuất hiện trong top 10 kết quả | Được AI chọn làm nguồn trả lời |
| Googlebot, Bingbot | GPTBot, ClaudeBot, PerplexityBot |
| Backlink, keyword density | Entity clarity, answer completeness |
| Organic click-through rate | AI citation rate, brand mention |
| Tùy chọn, hỗ trợ rich snippets | Bắt buộc, đặc biệt FAQ và HowTo |
| Tự do, ưu tiên từ khóa mục tiêu | Q&A structure, definitive statements |
Hình 2 mô tả quy trình xử lý kỹ thuật của một AI search engine khi tiếp cận nội dung web. Quá trình gồm bốn giai đoạn: web crawl (kiểm soát qua robots.txt), HTML parsing (phân tích cấu trúc ngữ nghĩa), schema extraction (trích xuất structured data), và LLM indexing (xây dựng chỉ số khả năng trích dẫn). Điều đáng chú ý là phần lớn website bị loại ngay tại giai đoạn đầu tiên do cấu hình robots.txt sai.

Hình 2. Quy trình xử lý của AI search engine. Khoảng 90% website bị loại ở Bước 1 do cấu hình robots.txt không cho phép AI crawlers truy cập.
Điểm then chốt cần hiểu là các AI crawler không xếp hạng trang web theo thuật toán PageRank. Thay vào đó, LLM đánh giá xem nội dung có thể được trích xuất và tổng hợp thành một câu trả lời mạch lạc hay không. Cấu trúc nội dung rõ ràng, khẳng định dứt khoát (definitive statements), và dữ liệu có thể kiểm chứng là những gì LLM tìm kiếm khi chọn nguồn trích dẫn.
3. Sáu yếu tố cốt lõi của AI Citability
Citability Score là chỉ số tổng hợp phản ánh mức độ phù hợp của nội dung website với các yêu cầu của AI khi cần trích dẫn nguồn. Dựa trên nghiên cứu thực nghiệm từ cộng đồng GEO và kết quả audit từ công cụ geo-seo-claude, sáu yếu tố kỹ thuật sau đây có tác động trực tiếp và có thể đo lường được đến khả năng được AI trích dẫn.
F1. Crawler Access (trọng số 30%) : Đây là điều kiện tiên quyết và cũng là lỗi phổ biến nhất. Nếu AI crawler không thể truy cập website do bị chặn trong robots.txt, toàn bộ nỗ lực tối ưu hóa các yếu tố khác đều trở nên vô nghĩa. Nhiều hosting provider tự động thêm cấu hình block một số bot vào robots.txt mà không thông báo với chủ website.
F2. Schema Markup (trọng số 35%): Schema.org markup là tập hợp các chuẩn dữ liệu có cấu trúc (structured data) được Google, Microsoft, Yahoo và Yandex cùng phát triển. Với GEO, Schema.org trở nên quan trọng hơn vì nó cung cấp cho AI một biểu diễn ngữ nghĩa rõ ràng về nội dung trang, không phụ thuộc vào việc AI có phân tích HTML phức tạp hay không. Đây là yếu tố có trọng số cao nhất trong tính toán Citability Score.
F3. Answer Completeness (trọng số 15%) : Trang web có trả lời trực tiếp và đầy đủ một câu hỏi cụ thể hay không là yếu tố quyết định thứ ba. AI ưu tiên các nguồn có thể cung cấp câu trả lời tự chứa (self-contained answer), không yêu cầu người đọc phải theo dõi nhiều trang để hiểu đầy đủ vấn đề.
F4. Heading Hierarchy (trọng số 15%) : Cấu trúc H1 đến H6 phải tuân theo thứ tự tuyến tính và nhất quán. AI parser dùng heading structure để xây dựng document outline, đây là một bản đồ ngữ nghĩa của trang. Khi heading bị nhảy cấp (chẳng hạn từ H1 nhảy thẳng xuống H3), document outline bị phá vỡ và AI mất khả năng phân đoạn nội dung theo chủ đề chính xác.
F5. Domain Authority (biến ngoại sinh): Số lượng và chất lượng backlink từ các nguồn uy tín vẫn là tín hiệu quan trọng mà AI sử dụng để đánh giá mức độ tin cậy của nguồn. Tuy nhiên, đây là yếu tố khó kiểm soát trực tiếp trong ngắn hạn nên thường được xếp vào chiến lược dài hạn.
F6. Brand Mentions (tín hiệu xác thực thực thể): Tần suất thương hiệu được đề cập trên các trang ngoài (external brand mentions) cung cấp cho AI tín hiệu xác thực rằng thực thể này thực sự tồn tại và có uy tín trong cộng đồng. Đây đặc biệt quan trọng với Entity Recognition,đây là khả năng AI nhận diện và liên kết tên thương hiệu với một tổ chức cụ thể.
Hình 3 so sánh cấu trúc heading đúng và sai, minh họa tác động trực tiếp đến khả năng AI parser xây dựng document outline:
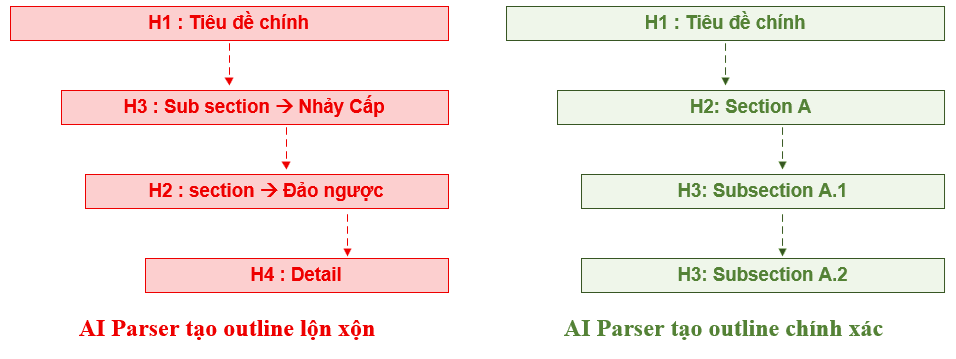
Hình 3. So sánh cấu trúc heading. Phía trái (SAI): nhảy cấp H1 → H3 và đảo ngược thứ tự phá vỡ document outline. Phía phải (ĐÚNG): thứ tự tuyến tính H1 → H2 → H3 → H3 cho phép AI xây dựng outline chính xác.
4. Cấu hình robots.txt cho AI Crawlers
robots.txt là file văn bản đặt tại root của website, quy định quyền truy cập của các web crawler. Theo chuẩn Robots Exclusion Protocol, mỗi crawler được định danh bằng User-agent string và nhận chỉ thị Allow hoặc Disallow cho các đường dẫn cụ thể. Các AI crawler sử dụng User-agent string riêng biệt, khác với các search engine crawler truyền thống như Googlebot hay Bingbot. Danh sách các AI crawler chính cần được cho phép truy cập bao gồm: GPTBot và ChatGPT-User từ OpenAI (phục vụ ChatGPT browsing và training data), ClaudeBot và anthropic-ai từ Anthropic (phục vụ Claude), Google-Extended (phục vụ AI Overview và training data cho Google), PerplexityBot từ Perplexity AI, và cohere-ai từ Cohere. Cấu hình chuẩn như sau:
</> text
# OpenAI — ChatGPT browsing và training
User-agent: GPTBot
Allow: /
User-agent: ChatGPT-User
Allow: /
# Anthropic — Claude
User-agent: ClaudeBot
Allow: /
User-agent: anthropic-ai
Allow: /
# Google — AI Overview và training
User-agent: Google-Extended
Allow: /
# Perplexity AI
User-agent: PerplexityBot
Allow: /
# Wildcard — cho phép tất cả
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /private/
Sitemap: https://example.com/sitemap.xml
Để kiểm tra tự động trạng thái của robots.txt, đoạn mã Python sau sử dụng thư viện chuẩn urllib.robotparser để phân tích cú pháp đúng chuẩn RFC, bao gồm xử lý đúng các trường hợp biên như wildcard và precedence rule:
</> python
from urllib.robotparser import RobotFileParser
def check_ai_crawler_access(site_url: str) -> dict:
rp = RobotFileParser()
rp.set_url(f"{site_url.rstrip('/')}/robots.txt")
rp.read()
crawlers = {
"GPTBot": "OpenAI ChatGPT",
"ClaudeBot": "Anthropic Claude",
"anthropic-ai": "Anthropic (training)",
"Google-Extended": "Google AI",
"PerplexityBot": "Perplexity AI",
}
results = {}
for agent, name in crawlers.items():
can_fetch = rp.can_fetch(agent, site_url)
results[agent] = {"name": name, "allowed": can_fetch}
return results
Cảnh báo quan trọng : Nếu robots.txt đang block GPTBot hoặc ClaudeBot, các chatbot tương ứng sẽ không có dữ liệu từ website để cite. Đây không phải vấn đề về ranking mà là vấn đề về khả năng tiếp cận hoàn toàn. Phần lớn website bị chặn vô tình do hosting provider thêm cấu hình mặc định.
5. Triển khai Schema.org Markup
Schema.org là một dự án cộng tác giữa Google, Microsoft, Yahoo và Yandex ra đời năm 2011, cung cấp một bộ từ vựng chuẩn để đánh dấu ngữ nghĩa nội dung web. Với GEO, Schema.org đóng vai trò quan trọng hơn so với SEO truyền thống vì nó cho phép AI đọc thông tin có cấu trúc trực tiếp mà không cần phân tích HTML phức tạp. Schema markup được triển khai dưới dạng JSON-LD (JavaScript Object Notation for Linked Data), đặt trong thẻ script với type="application/ld+json".
Có bốn loại schema cần triển khai theo thứ tự ưu tiên. Organization schema là nền tảng bắt buộc cho mọi website, giúp AI nhận diện thực thể tổ chức. FAQPage schema có tác động cao nhất đến khả năng được trích dẫn vì cung cấp cặp câu hỏi và câu trả lời định dạng sẵn. Article schema dành cho các trang nội dung bài viết với metadata đầy đủ về tác giả và thời gian. HowTo schema phù hợp với các trang hướng dẫn từng bước.
- Organization Schema : bắt buộc trên mọi website, phải được đặt trong phần head của trang chủ. Các trường quan trọng nhất gồm name (tên tổ chức), url (URL chính thức), description (mô tả ngắn gọn), và sameAs (danh sách các trang mạng xã hội chính thức). Trường sameAs đặc biệt quan trọng vì nó giúp AI liên kết các đề cập về thương hiệu trên các nền tảng khác nhau về cùng một thực thể:
</> javascript
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Tên tổ chức",
"url": "https://example.com",
"logo": {
"@type": "ImageObject",
"url": "https://example.com/logo.png",
"width": 300, "height": 100
},
"description": "Mô tả ngắn gọn, tối đa 160 ký tự.",
"foundingDate": "2020",
"sameAs": [
"https://www.facebook.com/yourpage",
"https://www.linkedin.com/company/yourcompany"
]
}
</script>
- FAQPage Schema: Đây là yếu tố quan trọng nhất cho AI citability. FAQPage schema là loại schema có tác động cao nhất đến khả năng được AI trích dẫn. Khi AI nhận được câu hỏi từ người dùng, nó ưu tiên nguồn có cấu trúc Q&A rõ ràng vì nội dung đó đã được định dạng sẵn theo dạng câu trả lời. Mỗi câu hỏi được định nghĩa trong phần tử Question với trường name (câu hỏi) và acceptedAnswer (câu trả lời đã được chấp nhận):
</> javascript
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "GEO là gì và khác với SEO như thế nào?",
"acceptedAnswer": {
"@type": "Answer",
"text": "GEO (Generative Engine Optimization) là...",
}
},
{
"@type": "Question",
"name": "Schema markup nào quan trọng nhất cho GEO?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Thứ tự ưu tiên: Organization, FAQPage, Article."
}
}
]
}
</script>
- Article Schema: chuyên dành cho các trang bài viết. Article schema cung cấp metadata đầy đủ về bài viết, đặc biệt các trường datePublished và dateModified giúp AI biết thông tin có còn current hay không. Trường author nên liên kết đến trang cá nhân của tác giả để tăng entity authority:
</> javascript
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Tiêu đề bài viết",
"author": {
"@type": "Person",
"name": "Tên tác giả",
"url": "https://example.com/author/ten"
},
"publisher": {
"@type": "Organization",
"name": "Tên tổ chức"
},
"datePublished": "2026-01-15T08:00:00+07:00",
"dateModified": "2026-04-01T10:00:00+07:00",
"wordCount": 2500
}
Validate Schema sau khi triển khai : Sau khi triển khai schema markup, cần validate bằng công cụ chính thức của Google tại search.google.com/test/rich-results. Ngoài ra, đoạn mã Python sau có thể tự động kiểm tra toàn bộ schema types đang được sử dụng trên một trang và xác định những loại còn thiếu:
</> python
import requests, json
from bs4 import BeautifulSoup
def audit_required_schemas(url: str) -> dict:
REQUIRED = {
"Organization": "Bắt buộc trên trang chủ",
"FAQPage": "Cần thiết cho AI Q&A matching",
"Article": "Cần trên các trang bài viết",
}
resp = requests.get(url, timeout=15)
soup = BeautifulSoup(resp.content, "html.parser")
scripts = soup.find_all("script",
{"type": "application/ld+json"})
found = []
for s in scripts:
try:
data = json.loads(s.string)
items = data.get("@graph", [data])
for item in items:
found.append(item.get("@type", ""))
except: pass
for t, desc in REQUIRED.items():
icon = "OK" if t in found else "MISSING"
print(f"{icon:8s} {t:20s} — {desc}")
6. Cấu trúc nội dung tối ưu cho AI Parsing
Ngoài markup kỹ thuật, cấu trúc HTML và văn phong nội dung cũng ảnh hưởng đáng kể đến khả năng AI parsing. LLM xử lý nội dung web theo thứ tự từ trên xuống và ưu tiên nội dung có cấu trúc rõ ràng. Có ba nguyên tắc kỹ thuật quan trọng cần áp dụng đồng thời.
Definitive statements : AI trích dẫn nội dung dạng definitive statement: câu khẳng định trực tiếp, rõ ràng, không mơ hồ. Thay vì viết "có thể X trong một số trường hợp", nên viết "X trong điều kiện Y". Câu hỏi tu từ, văn phong vòng vo, hoặc nội dung không kết luận rõ ràng có xác suất được cite thấp hơn đáng kể. Kết luận và số liệu quan trọng nhất nên được đặt ở đầu đoạn hoặc đầu bài, không phải ở cuối.
Heading hierarchy nhất quán: HTML heading phải tuân theo thứ tự tuyến tính H1 đến H6, không được nhảy cấp. Lỗi phổ biến nhất là dùng H1 rồi nhảy xuống H3 vì lý do thiết kế, làm hỏng document outline mà AI parser phụ thuộc vào. Mỗi trang chỉ có đúng một H1 chứa primary keyword của trang đó.
FAQ section: Đây là phần có cấu trúc quan trọng nhất. Việc thêm một phần FAQ vào cuối mỗi trang nội dung quan trọng là cách hiệu quả nhất để tăng Citability Score trong ngắn hạn. FAQ section kết hợp với FAQPage Schema tạo ra hai lớp tín hiệu cho AI: một lớp từ nội dung HTML và một lớp từ structured data. Mỗi trang nên có ít nhất 3-5 câu hỏi liên quan trực tiếp đến nội dung chính của trang đó. Template HTML tối ưu cho một trang nội dung được viết như sau, trong đó FAQ section được đánh dấu đồng thời bằng microdata (itemscope/itemprop) để tương thích tối đa với các AI crawler khác nhau:
</> html
<article itemscope itemtype="https://schema.org/Article">
<!-- H1: duy nhất, chứa primary keyword -->
<h1 itemprop="headline">
Tiêu đề chính xác, cụ thể
</h1>
<!-- Abstract: đặt kết luận lên đầu -->
<div class="abstract" itemprop="description">
<p>[Kết luận chính của bài]</p>
<p>[Số liệu xác thực cụ thể]</p>
</div>
<h2>Section chính — tên rõ ràng</h2>
<p>Nội dung definitive statement...</p>
<h3>Subsection cụ thể</h3>
<p>Chi tiết kỹ thuật...</p>
<!-- FAQ Section — quan trọng nhất -->
<section class="faq"
itemscope itemtype="https://schema.org/FAQPage">
<h2>Câu hỏi thường gặp</h2>
<div itemscope itemprop="mainEntity"
itemtype="https://schema.org/Question">
<h3 itemprop="name">Câu hỏi cụ thể?</h3>
<div itemscope itemprop="acceptedAnswer"
itemtype="https://schema.org/Answer">
<p itemprop="text">Câu trả lời trực tiếp.</p>
</div>
</div>
</section>
</article>
7. Công cụ geo-seo-claude: Cài đặt và Sử dụng
geo-seo-claude là một Claude Code skill mã nguồn mở, được phát triển bởi cộng đồng và hoạt động trong môi trường Claude Code. Công cụ này tự động hóa toàn bộ quy trình GEO audit bằng cách kết hợp khả năng crawling, parsing HTML, phân tích Schema markup, và đánh giá Citability Score thành một pipeline duy nhất.
Công cụ được cài đặt qua npx hoặc thủ công qua git clone, sau đó được copy vào thư mục skills của Claude Code:
Cài đặt
</> bash
# Cài đặt nhanh qua npx
npx skills add zubair-trabzada/geo-seo-claude
# Hoặc cài đặt thủ công
git clone https://github.com/zubair-trabzada/geo-seo-claude
cp -r geo-seo-claude/skills/* ~/.claude/skills/
# Kiểm tra cài đặt thành công
ls ~/.claude/skills/
# Output mong đợi: geo-seo-audit.md
Sử dụng trong Claude Code
Sau khi cài đặt, skill được kích hoạt thông qua prompt thông thường trong Claude Code. Claude Code sẽ tự động load skill, crawl website, phân tích cấu trúc, và tạo báo cáo:
</> prompt
# Audit cơ bản
Tiến hành GEO-SEO audit cho website example.com
# Audit chuyên sâu với báo cáo PDF
Tiến hành GEO-SEO audit đầy đủ cho example.com,
tạo báo cáo PDF với điểm số chi tiết cho từng
hạng mục và danh sách action items ưu tiên.
# Audit một trang cụ thể
Audit GEO cho https://example.com/san-pham/abc,
tập trung vào Schema markup và FAQ optimization.
Xây dựng standalone audit script
Đối với trường hợp cần chạy audit độc lập không phụ thuộc Claude Code, đoạn mã Python sau tổng hợp toàn bộ các kiểm tra vào một class AuditResult duy nhất với phương thức tính điểm có trọng số:
</> python
from dataclasses import dataclass, field
import requests, json
from urllib.robotparser import RobotFileParser
from bs4 import BeautifulSoup
@dataclass
class AuditResult:
url: str
crawler_access: dict = field(default_factory=dict)
schema_types: list = field(default_factory=list)
heading_issues: list = field(default_factory=list)
faq_count: int = 0
citability_score: float = 0.0
def compute_score(self):
score = 0.0
# F1: Crawler access (30 pts)
key_crawlers = ["GPTBot","ClaudeBot","PerplexityBot"]
allowed = sum(1 for c in key_crawlers
if self.crawler_access.get(c, False))
score += (allowed / len(key_crawlers)) * 30
# F2: Schema markup (35 pts)
for s, pts in [("Organization",15),
("FAQPage",12),("Article",8)]:
if s in self.schema_types: score += pts
# F3: Heading (15 pts)
issues = len(self.heading_issues)
score += max(0, 15 - issues * 3)
# F4: FAQ sections (20 pts)
score += min(20, self.faq_count * 4)
self.citability_score = round(score, 1)
return self.citability_score
8. Audit Checklist và Đo Lường Kết Quả
Quá trình triển khai GEO tối ưu được chia thành ba nhóm theo mức độ ưu tiên và thời gian thực hiện. Nhóm đầu tiên tập trung vào các lỗi kỹ thuật cơ bản có thể khắc phục trong vòng hai giờ. Nhóm thứ hai bao gồm các cải tiến cần lên kế hoạch trong một ngày làm việc. Nhóm thứ ba là các hoạt động dài hạn cần theo dõi liên tục.
Ưu tiên cao :
Kiểm tra robots.txt tại yoursite.com/robots.txt, đảm bảo GPTBot, ClaudeBot, PerplexityBot không bị block.
Thêm Organization Schema JSON-LD vào <head> của trang chủ với đầy đủ name, url, description, sameAs.
Kiểm tra heading hierarchy: không được nhảy cấp (H1→H3 không có H2 ở giữa).
Validate schema markup tại search.google.com/test/rich-results.
Ưu tiên vừa:
Xác định 5-10 câu hỏi thường gặp cho từng trang quan trọng và thêm FAQPage Schema tương ứng.
Thêm Article Schema cho tất cả trang bài viết với đầy đủ author, datePublished, dateModified.
Thêm HowTo Schema cho các trang hướng dẫn từng bước.
Cấu trúc lại nội dung theo dạng definitive statement: kết luận và số liệu quan trọng đặt đầu bài.
Ưu tiên dài hạn:
Theo dõi brand mention trong các AI responses bằng cách kiểm tra thủ công định kỳ.
Build authority signals: xuất bản trên các nền tảng uy tín có backlink về website chính.
Cập nhật dateModified trong schema khi nội dung thay đổi để AI nhận biết thông tin còn current.
Đo lường kết quả sau tối ưu: Do chưa có cơ chế đo lường AI citation rate tự động chính thức, phương pháp thực tế nhất là thiết lập một tập 20-30 câu hỏi liên quan đến lĩnh vực của website, hỏi cùng bộ câu hỏi đó trên ChatGPT, Perplexity và Gemini mỗi tháng một lần, và ghi lại số lần website được cite trong câu trả lời. Tỷ lệ citation sau khi tối ưu robots.txt và triển khai FAQ Schema thường tăng đáng kể sau 2-4 tuần.
</> python
class CitationTracker:
def record_session(self, domain, platform,
queries_tested, citations_found,
notes=""):
session = {
"date": datetime.now().isoformat()[:10],
"domain": domain,
"platform": platform,
"queries_tested": queries_tested,
"citations_found": citations_found,
"citation_rate": round(
citations_found/queries_tested*100, 1)
}
self.data["sessions"].append(session)
self.data_file.write_text(
json.dumps(self.data, ensure_ascii=False))
# Sử dụng sau mỗi lần kiểm tra
tracker = CitationTracker()
tracker.record_session(
domain="example.com",
platform="ChatGPT",
queries_tested=25,
citations_found=7,
notes="Sau 4 tuần tối ưu GEO")
GEO là lĩnh vực còn non trẻ và đang thay đổi nhanh. Không có cơ chế chính thức nào để đo lường AI citation rate tự động. Các cải thiện kỹ thuật thường mất 2-4 tuần để phản ánh trong hành vi của AI, và kết quả không đồng đều giữa các AI platform khác nhau. Triển khai robots.txt và Organization Schema là hai bước đầu tiên nên thực hiện ngay do có tác động cao và công sức thấp.
Lời cuối
GEO đại diện cho một sự dịch chuyển căn bản trong cách website cần được tối ưu hóa để duy trì khả năng hiện diện trong kỷ nguyên AI search. Trong khi SEO truyền thống tiếp tục quan trọng cho việc duy trì traffic hữu cơ từ Google Search, GEO giải quyết một chiều cạnh mới và ngày càng quan trọng hơn của khả năng tiếp cận nội dung: khả năng được AI trích dẫn.
Trong sáu yếu tố cốt lõi được phân tích, Crawler Access và Schema Markup nổi bật là hai yếu tố có thể kiểm soát ngay lập tức với tác động trực tiếp và có thể đo lường được. Phần lớn website, đặc biệt tại thị trường Việt Nam, chưa triển khai đúng robots.txt cho AI crawlers và hoàn toàn thiếu Schema.org markup, đây là cơ hội lợi thế cạnh tranh đáng kể cho các website tiến hành tối ưu sớm.
Về mặt kỹ thuật, GEO không yêu cầu thay đổi kiến trúc hệ thống mà chủ yếu là bổ sung các lớp structured data và điều chỉnh cấu hình. Chi phí triển khai ban đầu thấp trong khi tiềm năng tăng khả năng hiện diện trong các AI platform ngày càng cao. Tuy nhiên, do đây là lĩnh vực còn mới và đang phát triển nhanh, cần theo dõi các cập nhật từ các AI provider về tiêu chí trích dẫn để điều chỉnh chiến lược kịp thời.