Bối cảnh: tại sao chạy model cục bộ lại có ý nghĩa?
Hai năm trước, nếu ai đó nói rằng bạn có thể chạy một model ngôn ngữ lớn 26 tỷ tham số trên laptop cá nhân với tốc độ 51 token mỗi giây , điều này nghe có vẻ khó tin lắm. Năm 2026, điều đó không chỉ khả thi mà còn trở nên thực sự tiện lợi nhờ sự kết hợp giữa kiến trúc Mixture-of-Experts và công cụ deployment được thiết kế lại từ đầu.
Bài viết của George Liu trình bày quy trình hoàn chỉnh để chạy Google Gemma 4 26B-A4B cục bộ thông qua LM Studio 0.4.0, sau đó kết nối nó với Claude Code để có môi trường lập trình AI hoàn toàn offline.
link bài gốc : https://ai.georgeliu.com/p/running-google-gemma-4-locally-with và https://ai.georgeliu.com/p/running-google-gemma-4-with-ollama
Đây không chỉ là hướng dẫn kỹ thuật mà còn là minh chứng cho một bước ngoặt trong khả năng tiếp cận công nghệ LLM cho người dùng cá nhân và doanh nghiệp không muốn phụ thuộc vào API của bên thứ ba. Giá trị thực tiễn của setup này rõ ràng: bảo mật dữ liệu hoàn toàn vì không có gì rời khỏi máy, không có chi phí API, không bị giới hạn bởi rate limit, và có thể chạy trong môi trường airgapped không có kết nối internet. Với những tổ chức xử lý dữ liệu nhạy cảm hoặc triển khai trong mạng nội bộ nghiêm ngặt, đây là một lựa chọn rất đáng cân nhắc.
Kiến trúc Mixture-of-Experts và lý do Gemma 4 26B-A4B là lựa chọn tối ưu
Để hiểu tại sao Gemma 4 26B-A4B hoạt động hiệu quả trên phần cứng consumer, cần nắm được sự khác biệt căn bản giữa kiến trúc Dense và Mixture-of-Experts. Trong model dense truyền thống, khi xử lý mỗi token, toàn bộ tham số của model được kích hoạt và tham gia tính toán. Với một model 26 tỷ tham số, điều đó có nghĩa là 26 tỷ phép nhân ma trận được thực hiện mỗi lần sinh ra một token.
Kiến trúc MoE thay đổi điều này bằng cách chia model thành nhiều expert chuyên biệt, mỗi expert phụ trách một vùng không gian biểu diễn khác nhau. Một router nhỏ ở đầu vào quyết định expert nào được kích hoạt cho token đang xử lý. Gemma 4 26B-A4B có tổng cộng 128 expert cộng với một shared expert, nhưng chỉ 8 trong số đó được kích hoạt cho mỗi token, tương đương khoảng 3.8 tỷ tham số hoạt động tại bất kỳ thời điểm nào.
Theo quy tắc kinh nghiệm được tác giả đề cập, chất lượng của một MoE model xấp xỉ một model dense có số tham số bằng căn bậc hai của tích số tham số tổng và số tham số active. Với 26B tổng và 3.8B active, con số này vào khoảng 10 tỷ tham số hiệu quả. Trên thực tế, benchmark cho thấy 26B-A4B đạt 82.6% trên MMLU Pro và 88.3% trên AIME 2026, chỉ kém nhẹ so với phiên bản dense 31B đạt 85.2% và 89.2% tương ứng.
Điểm benchmark MMLU Pro và AIME 2026 cho toàn bộ dòng model Gemma 4. Model 26B-A4B đạt gần ngang bằng phiên bản 31B dense trong khi yêu cầu ít tài nguyên hơn đáng kể.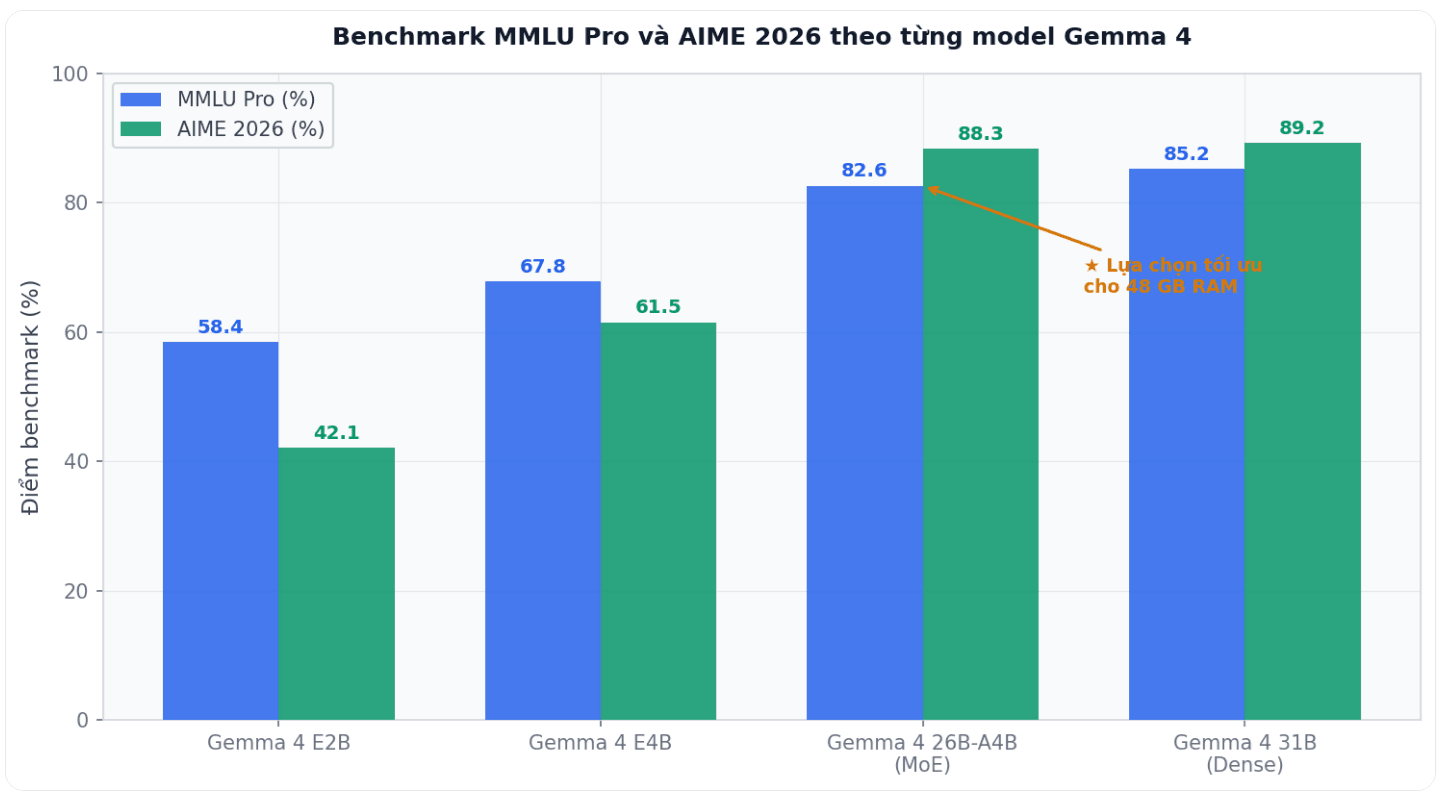
Hai model với hậu tố E (E2B và E4B) sử dụng layered embeddings tối ưu cho triển khai trên thiết bị di động và là các model duy nhất trong dòng hỗ trợ audio natively. Điểm benchmark của chúng thấp hơn vì đây là đánh đổi có chủ ý giữa hiệu suất và kích thước để phù hợp với phần cứng nhúng.
Vị trí của 26B-A4B trong bức tranh LLM tổng thể
Điểm thú vị nhất của Gemma 4 26B-A4B không phải là điểm benchmark tuyệt đối mà là tỷ lệ giữa hiệu suất và tài nguyên yêu cầu. Đây là nơi MoE tạo ra lợi thế thực sự so với các model dense cùng hạng. Elo Rating so với tổng số tham số các model LLM open-weight có reasoning support. Gemma 4 26B-A4B nằm trong vùng hiệu quả cao ở góc trên bên trái, đạt Elo ~1441 với chỉ 26B tham số tổng.
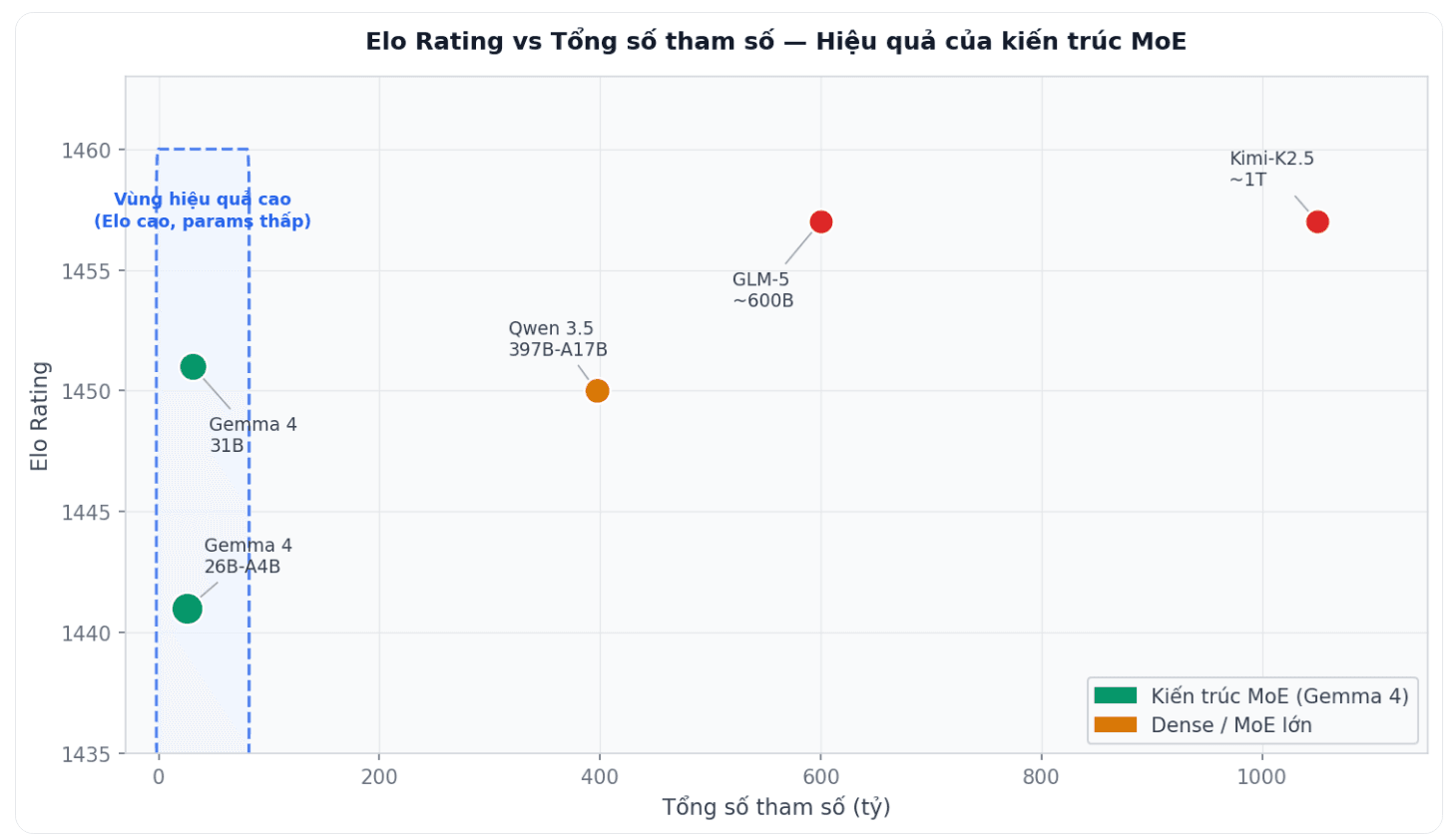
Nhìn vào đồ thị, Gemma 4 26B-A4B đạt Elo khoảng 1441, ngang với Qwen 3.5 397B-A17B (Elo ~1450) trong khi tổng số tham số chỉ bằng 1/15. Để đạt điểm Elo tương tự với kiến trúc thuần túy, GLM-5 cần khoảng 600 tỷ tham số và Kimi-K2.5 vượt qua 1 nghìn tỷ. Đây là lý do tác giả nhận định MoE đang làm thay đổi quy tắc cho deployment cá nhân: không cần cluster server để cạnh tranh với các model khổng lồ.
Với MacBook M4 Pro 48 GB unified memory, model 31B dense sẽ tiêu tốn nhiều bộ nhớ hơn và chạy chậm hơn vì mọi tham số đều tham gia tính toán. Model E4B nhẹ hơn nhưng kém về chất lượng đầu ra. Phiên bản 26B-A4B cung cấp context window lên đến 256K token, vision support cho phân tích screenshot và diagram, native tool use và function calling, cùng các chế độ reasoning có thể tùy chỉnh. Đây là lý do cụ thể mà nó đc chọn làm backend cho Claude Code.
LM Studio 0.4.0 và kiến trúc mới dựa trên daemon
LM Studio từ lâu đã là công cụ desktop phổ biến để chạy model cục bộ. Tuy nhiên phiên bản 0.4.0 là một cuộc tái kiến trúc thực sự chứ không chỉ là bổ sung tính năng.
Cải tiến cốt lõi là việc tách inference engine thành một server độc lập tên llmster chạy như daemon nền. Trước đây, mọi tương tác với model đều phải qua giao diện đồ họa. Với 0.4.0, CLI lms cung cấp đầy đủ khả năng download, load, run và chat với model hoàn toàn qua terminal, không cần mở GUI. Điều này mở ra việc sử dụng trên remote server qua SSH, trong CI/CD pipeline, và trong môi trường headless.
Ngoài daemon llmster và CLI lms, phiên bản này bổ sung continuous batching cho phép nhiều request song song không cần xếp hàng, stateful REST API qua endpoint /v1/chat có khả năng lưu conversation history giữa các request, tích hợp Model Context Protocol (MCP), và đặc biệt là endpoint tương thích hoàn toàn với Anthropic API. Endpoint Anthropic-compatible chính là điểm then chốt cho phép kết nối Claude Code với Gemma 4 local.
Cài đặt và khởi động
</> Terminal - Bash
# Bước 1: Cài đặt CLI lms
# Linux / macOS
curl -fsSL https://lmstudio.ai/install.sh | bash
# Windows (PowerShell)
irm https://lmstudio.ai/install.ps1 | iex
# Bước 2: Khởi động daemon nền
lms daemon up
# Bước 3: Cập nhật inference runtime (macOS)
lms runtime update llama.cpp
lms runtime update mlx
# Bước 4: Tải model Gemma 4 26B-A4B (Q4_K_M, ~18 GB)
lms get google/gemma-4-26b-a4bSau khi download hoàn tất, kiểm tra model đã được nạp vào bộ nhớ bằng lms ps. Output điển hình:
</> lms ps output (text)
IDENTIFIER MODEL STATUS SIZE CONTEXT PARALLEL TTL
google/gemma-4-26b-a4b google/gemma-4-26b-a4b IDLE 17.99 GB 48000 2 60m / 1hTham số TTL (time-to-live) tự động unload model sau 60 phút không có request, giải phóng RAM mà không cần thao tác thủ công. Đây là chi tiết nhỏ nhưng rất thực dụng trong môi trường development khi người dùng thường xuyên chuyển giữa các tác vụ.
Phân tích bộ nhớ: tính toán ngân sách RAM cho context window
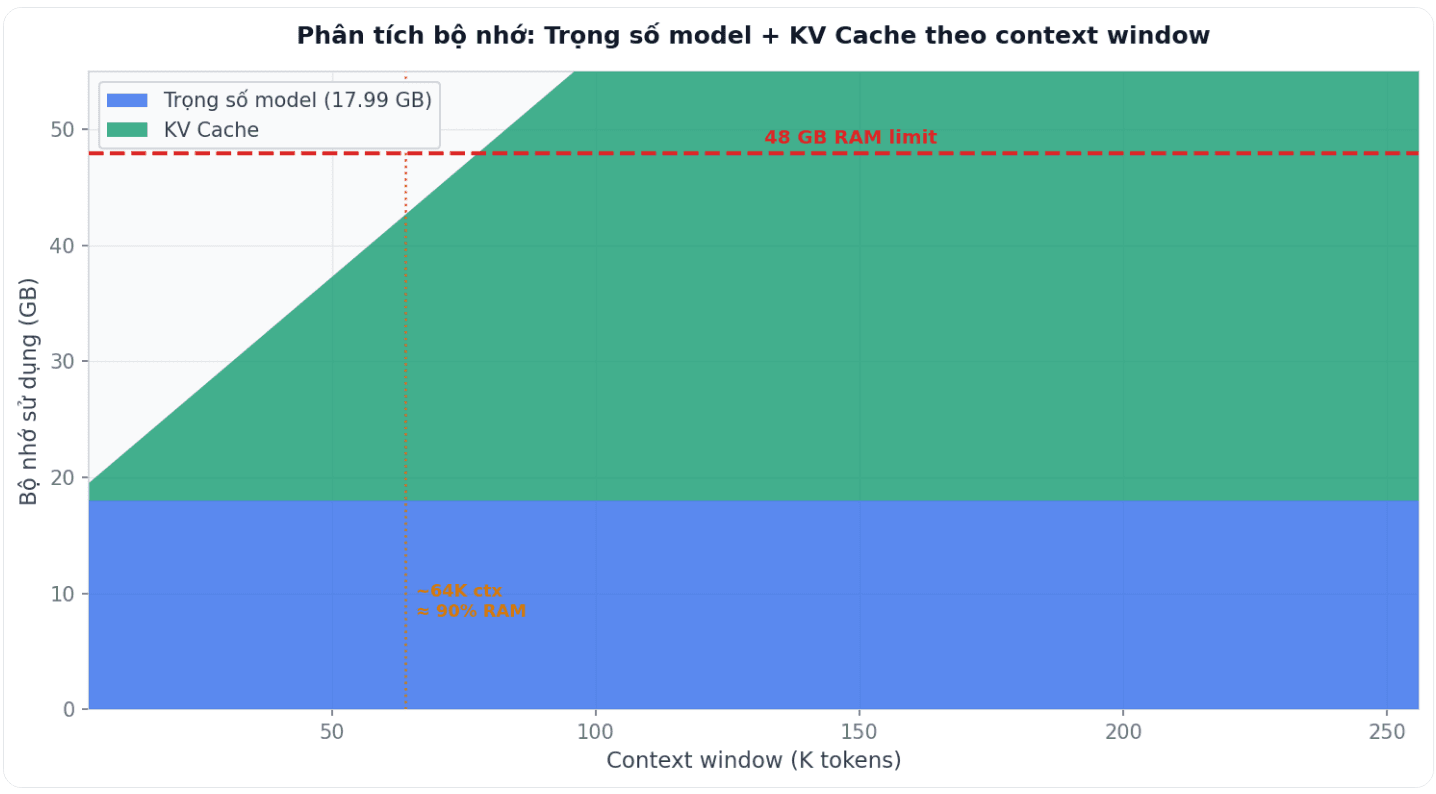
Một trong những điểm kỹ thuật quan trọng nhất trong bài viết là hướng dẫn tính toán lượng RAM cần thiết theo context window. Đây không phải chi tiết mà nhiều hướng dẫn đề cập, nhưng nó quyết định trực tiếp đến chất lượng trải nghiệm khi dùng Gemma 4 cho các tác vụ có context dài như code analysis hay document processing.
Bộ nhớ tổng cần thiết gồm hai thành phần chính: trọng số model cố định (17.99 GB cho bản Q4_K_M) và KV cache biến thiên theo context window. KV cache lưu trữ key và value tensor của attention cho mỗi token trong context, cho phép không phải tính lại khi sinh các token tiếp theo. Hình bên dưới phân tích bộ nhớ theo context window cho Gemma 4 26B-A4B trên 48 GB unified memory. Vùng màu xanh là trọng số model cố định (17.99 GB), vùng teal là KV cache tăng dần. Đường đỏ là giới hạn 48 GB RAM.
Công thức ước tính KV cache và script Python kiểm tra từng ngưỡng context:
</> python
def estimate_memory(
context_k: int,
model_weights_gb: float = 17.99,
num_layers: int = 46,
num_kv_heads: int = 8,
head_dim: int = 256,
dtype_bytes: int = 2) -> dict:
"""
Ước tính tổng RAM cần cho Gemma 4 26B-A4B.
context_k: số nghìn token (ví dụ 48 cho 48K, 256 cho 256K)
"""
seq_len = context_k * 1024
# KV cache = 2 * layers * kv_heads * head_dim * seq_len * bytes
kv_bytes = 2 * num_layers * num_kv_heads * head_dim * seq_len * dtype_bytes
kv_gb = kv_bytes / 1e9
total_gb = model_weights_gb + kv_gb
return {
"context_k": context_k,
"kv_cache_gb": round(kv_gb, 2),
"total_gb": round(total_gb, 2),
"remaining_gb": round(48.0 - total_gb, 2),
"feasible": total_gb < 48.0
}
# Kiểm tra các ngưỡng context phổ biến
for ctx in [16, 32, 48, 64, 128, 256]:
r = estimate_memory(ctx)
status = "OK " if r["feasible"] else "SWAP"
print(f"{ctx:4d}K KV {r['kv_cache_gb']:.2f} GB"
f" tổng {r['total_gb']:.2f} GB {status}"
f" còn dư {r['remaining_gb']:+.2f} GB")
Output thực tế khi chạy script cho thấy context 48K tốn khoảng 18.75 GB (model 17.99 + KV 0.76 GB), còn dư gần 29 GB cho OS và ứng dụng khác. Context 256K đẩy KV cache lên khoảng 4 GB, tổng gần 22 GB, vẫn trong ngưỡng an toàn. Tác giả gợi ý dùng context 48K cho chat thông thường và chỉ mở rộng lên 128-256K khi thực sự cần phân tích tài liệu dài.
Lưu ý về Speculative Decoding với MoE: Bài viết nhấn mạnh rằng speculative decoding là ý tưởng tệ cho kiến trúc MoE. Speculative decoding dùng một model nhỏ hơn để đề xuất token, sau đó model lớn verify. Với model dense, draft model thường có cùng kiến trúc thu nhỏ nên phân phối token khá tương đồng. Với MoE, expert routing của draft model và target model gần như không match nhau, khiến tỷ lệ accept thấp và overhead của bước verify không đáng. Nên tắt speculative decoding hoàn toàn khi dùng Gemma 4 26B-A4B.
Kho model cục bộ và đặc điểm từng kiến trúc
Dung lượng disk của 10 model trong lms ls. Model MoE (màu vàng) chiếm phần lớn không gian nhưng cung cấp số tham số effective cao hơn nhiều so với kích thước file. Nhìn vào danh sách, Qwen 3.5 35B-A3B chỉ chiếm 22.07 GB cho 35 tỷ tham số tổng với 3 tỷ active. GLM-4.7 Flash là model 30 tỷ tham số MoE nặng nhất trong danh sách ở 24.36 GB. Gemma 4 26B-A4B với 17.99 GB là điểm cân bằng tốt giữa chất lượng và kích thước. Các model non-MoE như GPT-OSS 20B chiếm 12-22 GB tùy phiên bản quantization, trong khi các model nhỏ như Llama 3.2 1B và Qwen2.5 0.5B chỉ cần dưới 1 GB.
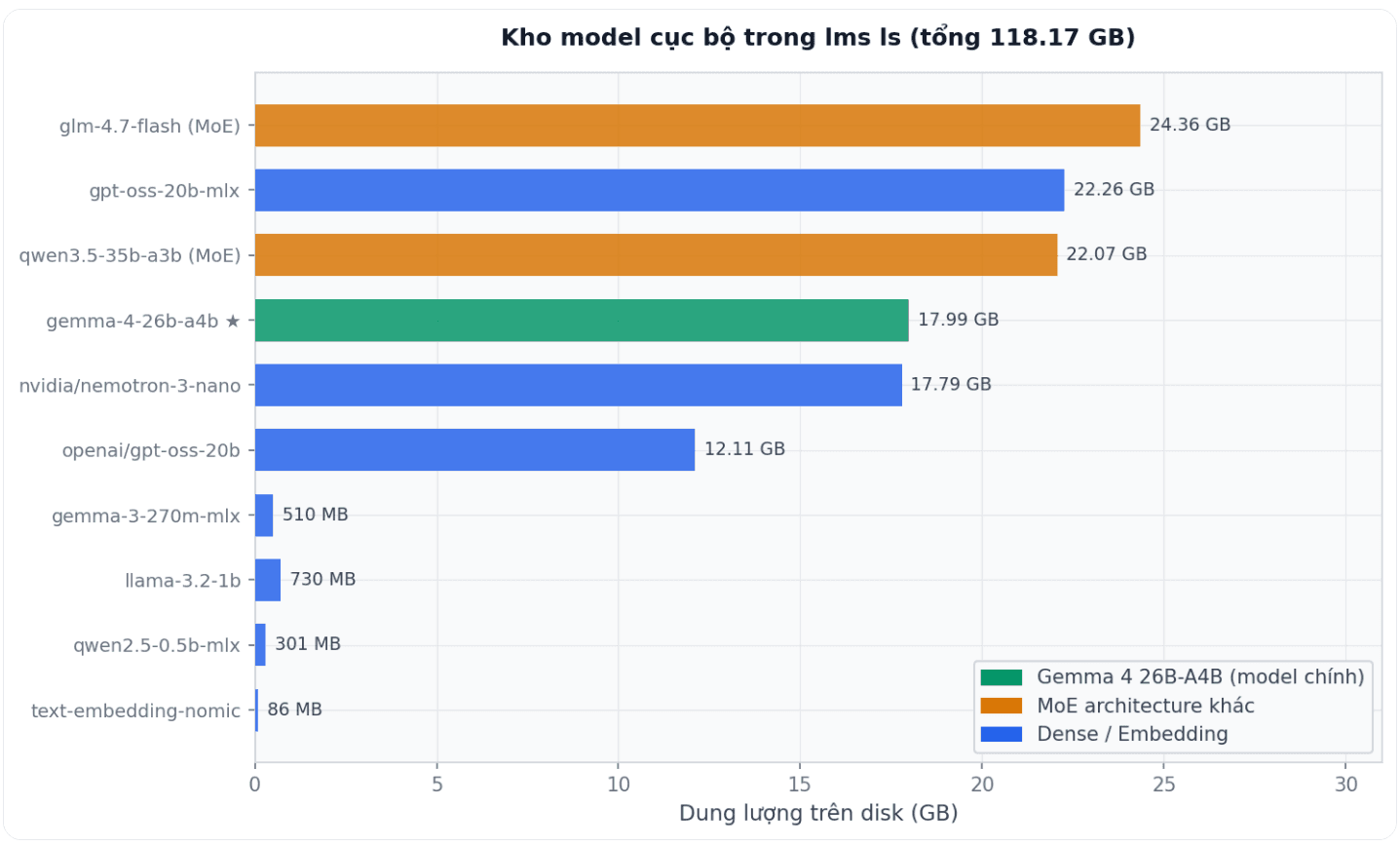
Điều này minh họa một điểm quan trọng: với cùng ngân sách disk 20-25 GB, một model MoE 30-35B tham số tổng cung cấp chất lượng hiệu quả gần ngang với một model dense 10-12B nhưng thường với tốc độ inference tốt hơn nhờ ít tham số active hơn.
Tốc độ inference theo use case và tại sao Claude Code chạy chậm hơn
Con số 51.35 token/giây từ lms chat google/gemma-4-26b-a4b --stats là điểm chuẩn baseline cho interactive chat. Tuy nhiên khi tích hợp với Claude Code, tác giả nhận thấy tốc độ giảm đáng kể. Đây là điều quan trọng cần hiểu rõ trước khi kỳ vọng vào workflow thực tế.
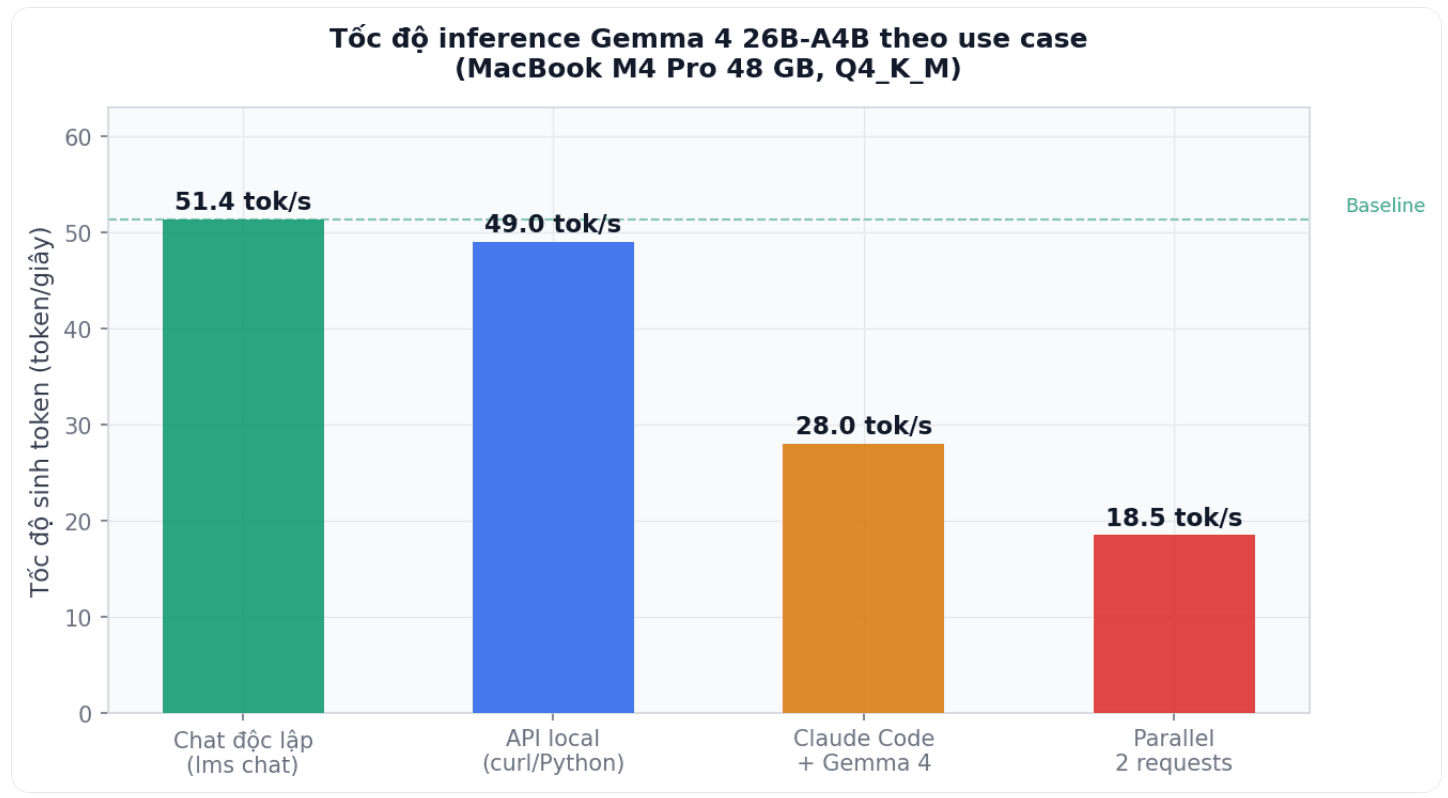
Nguyên nhân của sự sụt giảm khi dùng với Claude Code là do agentic workflow tạo ra những đặc điểm inference rất khác so với chat đơn giản. Claude Code liên tục mở rộng context với tool output, file content và conversation history. Mỗi tool call tạo ra một request mới với context dài hơn, làm tăng thời gian prefill (xử lý input tokens). Ngoài ra, Claude Code thường gửi nhiều short-burst request liên tiếp thay vì một request dài, làm tăng overhead của Time to First Token.
Với API call đơn giản qua curl hoặc Python client, tốc độ gần sát baseline vì không có overhead quản lý state. Khi chạy hai request song song (parallel=2 trong config), throughput tổng tăng nhưng tốc độ mỗi request giảm do phải chia sẻ compute budget.
Output --stats được ghi lại trong bài viết: Stop Reason: eosFound, Tokens/Second: 51.35, Time to First Token: 1.551s, Prompt Tokens: 39, Predicted Tokens: 176, Total Tokens: 215. Time to first token 1.55 giây là mức chấp nhận được cho chat tương tác. Với context dài hơn (prefill nhiều token hơn), TTFT có thể tăng lên 3-5 giây nhưng tốc độ generation sau đó không thay đổi nhiều.
Kết nối Claude Code với Gemma 4 qua Anthropic-compatible endpoint
Phần quan trọng nhất về mặt kỹ thuật trong bài viết là cách kết nối Claude Code với Gemma 4 đang chạy local. LM Studio 0.4.0 cung cấp endpoint tương thích với Anthropic API, có nghĩa là bất kỳ client nào dùng Anthropic SDK đều có thể trỏ đến local server thay vì cloud API của Anthropic.
Bài viết dùng lệnh claude-lm thay thế cho lệnh claude thông thường. Đây là một shell alias trỏ biến môi trường ANTHROPIC_BASE_URL về local endpoint của LM Studio:
</> bash
# Thêm vào ~/.bashrc hoặc ~/.zshrc
alias claude-lm='ANTHROPIC_BASE_URL=http://localhost:1234 \
ANTHROPIC_API_KEY=lm-studio \
ANTHROPIC_MODEL=google/gemma-4-26b-a4b \
claude'
# Kiểm tra daemon đang chạy
lms ps
# Chạy Claude Code qua Gemma 4 local
claude-lmEndpoint của LM Studio mặc định lắng nghe trên cổng 1234. API key có thể là bất kỳ chuỗi nào vì LM Studio không validate authentication khi chạy local. Model name cần khớp với identifier trong lms ls. Để kiểm tra kết nối qua Python SDK:
</> python
import anthropic
# Trỏ client về LM Studio local endpoint
client = anthropic.Anthropic(
api_key="lm-studio",
base_url="http://localhost:1234"
)
response = client.messages.create(
model="google/gemma-4-26b-a4b",
max_tokens=512,
messages=[{
"role": "user",
"content": "Giải thích kiến trúc Mixture-of-Experts trong 3 câu."
}]
)
print(response.content[0].text)
print(f"Input tokens: {response.usage.input_tokens}")
print(f"Output tokens: {response.usage.output_tokens}")
Điểm tinh tế là API key lm-studio không thực sự được xác thực; LM Studio chấp nhận bất kỳ giá trị nào cho header Authorization khi chạy trong local mode. Trong môi trường production hoặc khi expose endpoint ra mạng nội bộ, cần cấu hình authentication riêng qua reverse proxy như nginx hoặc Caddy.
Ứng dụng thực tế và giới hạn của setup này
Setup Gemma 4 cục bộ qua LM Studio phù hợp nhất cho các tác vụ cần bảo mật dữ liệu cao, không có kết nối internet, hoặc cần kiểm soát hoàn toàn về latency và chi phí. Code review trong môi trường có NDA nghiêm ngặt, phân tích tài liệu nội bộ, và prototyping trong mạng airgapped là những use case có giá trị rõ ràng.
Tuy nhiên có những giới hạn thực tế cần thừa nhận. Tốc độ 51 token/giây, trong khi ấn tượng cho local inference, vẫn thấp hơn nhiều so với cloud API. Claude Sonnet 4 qua Anthropic API thường đạt 80-120 token/giây với latency thấp hơn. Khi context dài hơn 32K token, thời gian prefill tăng đáng kể và trải nghiệm bắt đầu trở nên chậm với tác vụ tương tác thời gian thực. Và không phải phần cứng nào cũng có 48 GB unified memory; đây vẫn là ngưỡng yêu cầu tương đối cao với người dùng phổ thông.
Bài viết của George Liu là minh chứng cho một hướng phát triển đang diễn ra trong AI infrastructure: ranh giới giữa cloud và edge inference ngày càng mờ nhạt, và các công cụ như LM Studio đang đẩy nhanh quá trình đó bằng cách làm cho local deployment trở nên đơn giản đến mức bất kỳ developer nào cũng có thể thử trong vài phút. Kiến trúc MoE chính là chất xúc tác kỹ thuật cho xu hướng này.